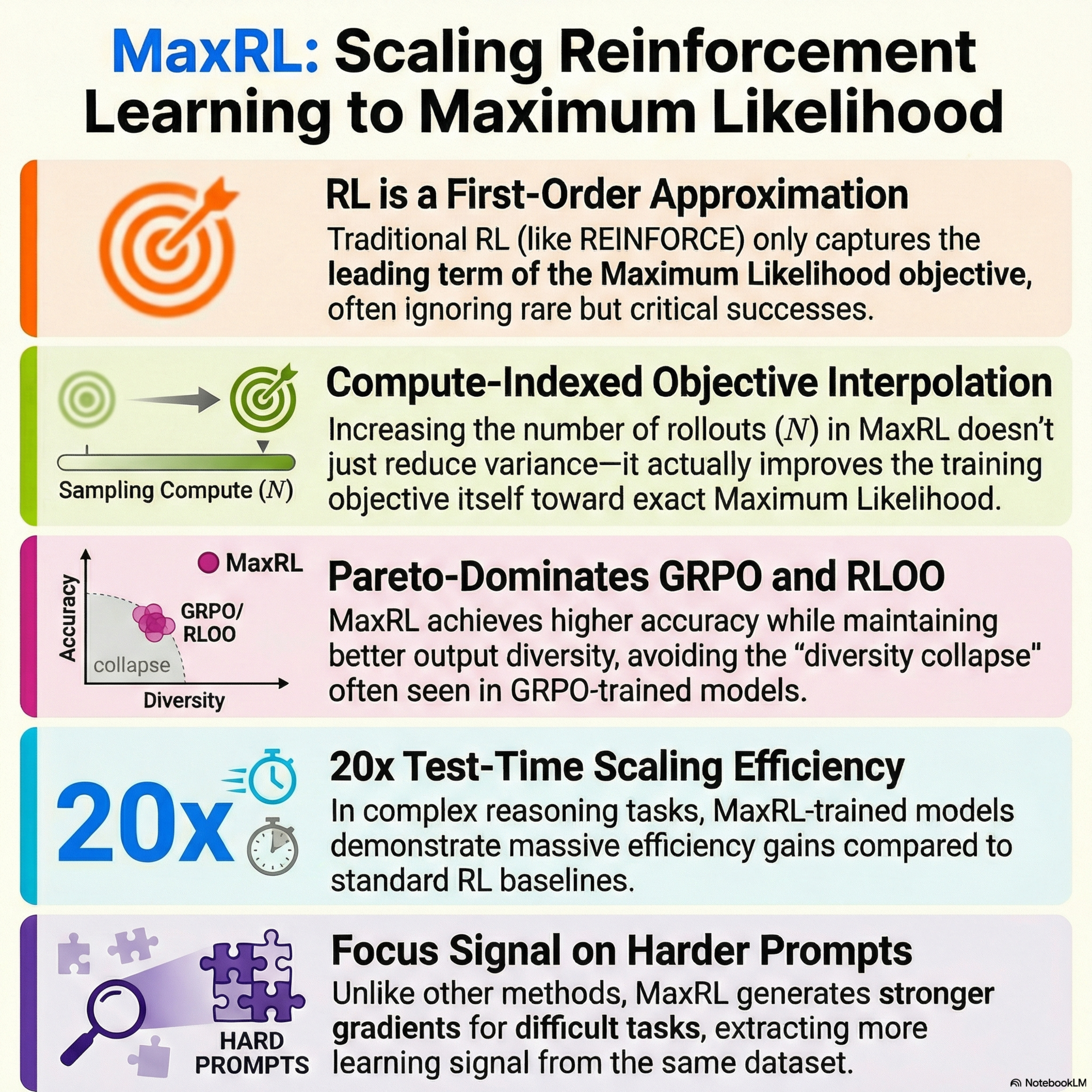
This paper introduces **Maximum Likelihood Reinforcement Learning (MaxRL)**, a novel framework designed to improve the training of models in tasks with binary feedback, such as mathematical reasoning and code generation. The authors argue that traditional **Reinforcement Learning (RL)** only optimizes a first-order approximation of the **maximum likelihood objective**, causing it to ignore harder problems where success is rare. **MaxRL** bridges this gap by using a compute-indexed objective that approaches exact maximum likelihood as more sampling resources are applied. By normalizing gradients based on successful outcomes rather than total samples, the method places greater emphasis on difficult tasks. Empirical results show that **MaxRL** significantly outperforms existing methods like **GRPO**, offering superior scaling with data and up to **20x gains in inference efficiency**. Ultimately, the framework mitigates the "distribution sharpening" and diversity loss often seen in large reasoning models trained with standard RL.