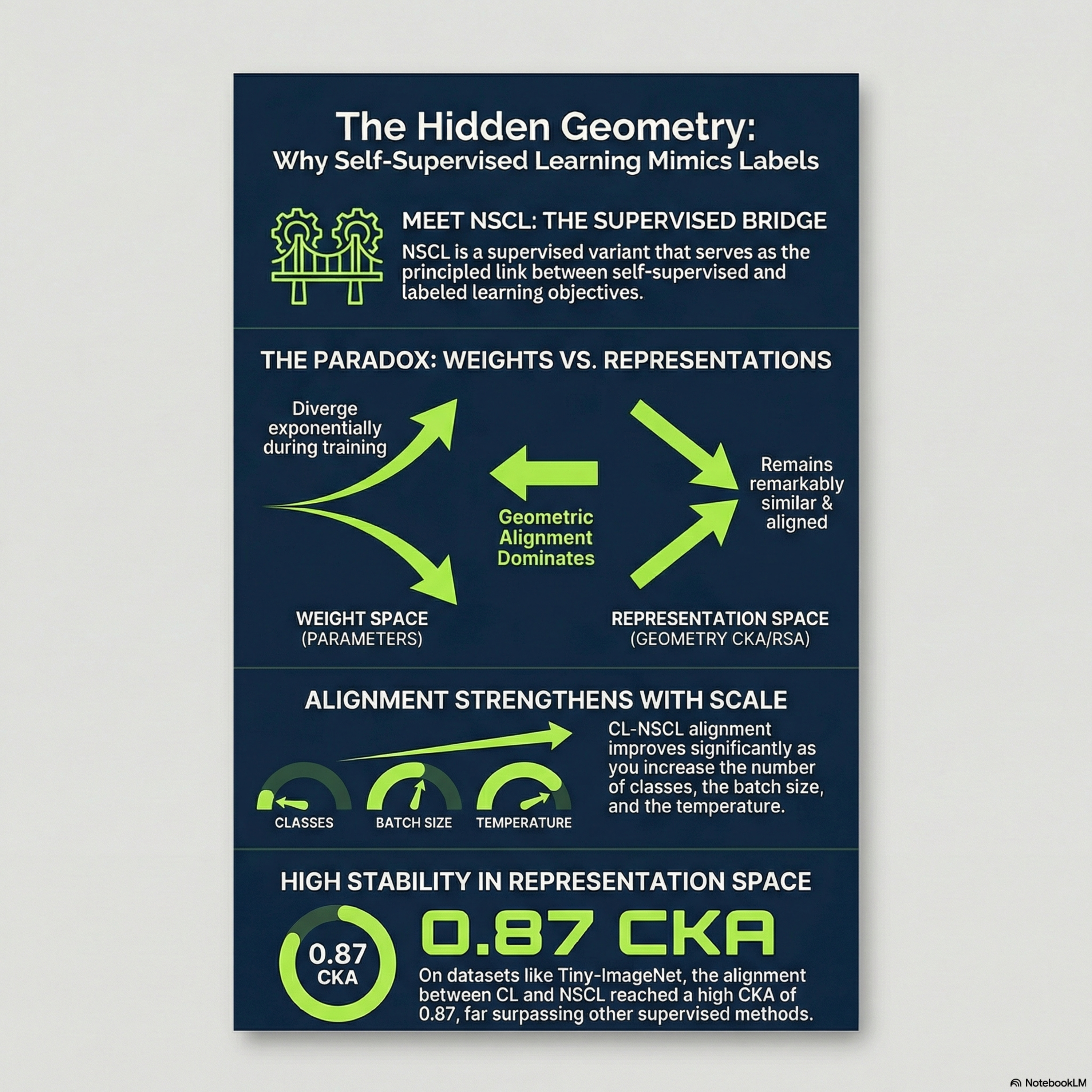
This research explores the mathematical and empirical relationship between Contrastive Learning (CL) and Non-Contrastive Supervised Contrastive Learning (NSCL). The authors demonstrate that CL and NSCL converge toward highly similar structural representations, a phenomenon they validate using metrics like Centered Kernel Alignment (CKA) and Representational Similarity Analysis (RSA). Their theoretical framework identifies key variables—such as temperature, batch size, and learning rate—that determine the proximity of these two methods in similarity space. Experimental results on datasets like CIFAR and ImageNet confirm that these training dynamics lead to nearly identical attention maps and feature distributions. Ultimately, the paper provides a formal proof that unsupervised contrastive models inherently approximate their supervised counterparts under specific optimization constraints.