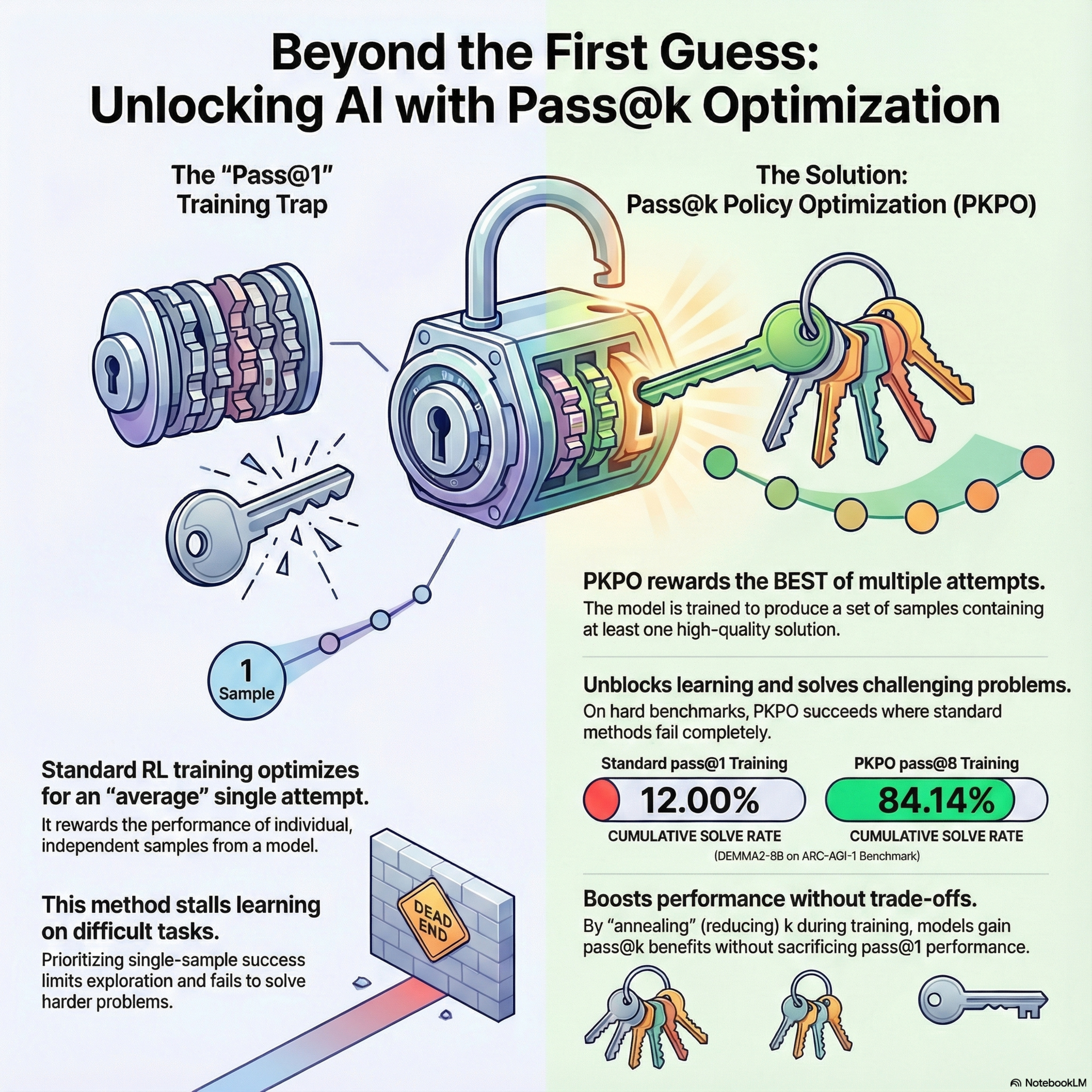
This paper introduces Pass-at-k Policy Optimization (PKPO), a novel Reinforcement Learning technique that shifts the focus from individual sample performance (pass@1) to optimizing the collective utility of a batch, quantified as the maximum expected reward (pass@k). This method is necessary because conventional RL under-utilizes sample diversity, limiting exploration and leading to stalled learning on difficult problems. PKPO's primary technical contribution is the derivation of novel, low-variance unbiased gradient estimators for the pass@k objective, which work robustly for any arbitrary $k$ with both binary and continuous rewards. The authors validate their transformation using open-source models like GEMMA2 and LLAMA3.1 on mathematical and coding benchmarks. Crucially, PKPO enables improved exploration, demonstrated by its ability to unblock learning and achieve superior performance, especially when the optimization target $k$ is annealed during training.