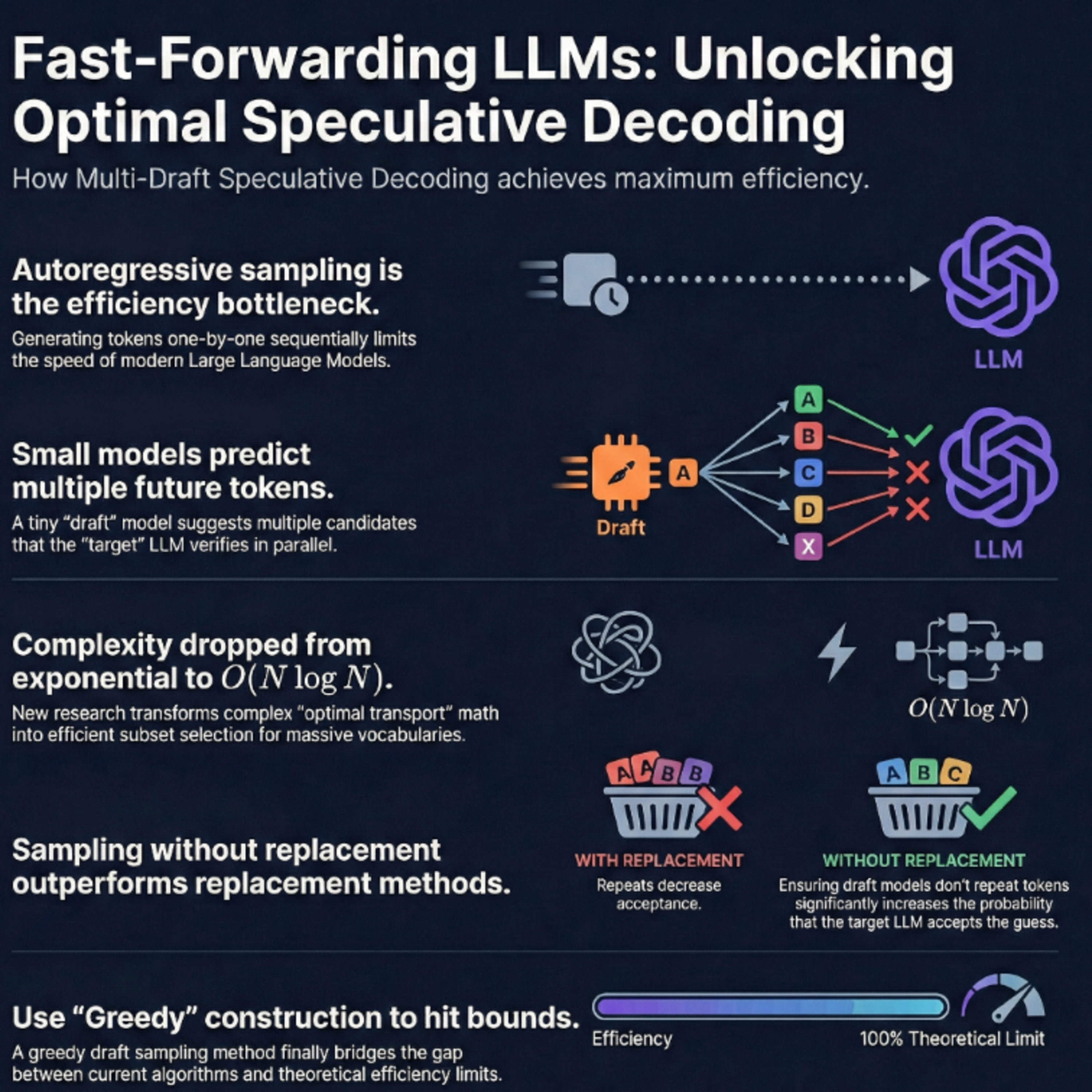
These sources explore advanced techniques for accelerating **Large Language Model (LLM) inference** through **speculative decoding**, a process where smaller "draft" models predict tokens for a larger "target" model to verify in parallel. A primary focus is **Multi-Draft Speculative Decoding (MDSD)**, which uses multiple draft sequences to increase the probability of acceptance and reduce latency. Researchers have introduced **SpecHub** to simplify complex optimization problems into manageable linear programming, while others utilize **optimal transport theory** and **q-convexity** to reach theoretical efficiency upper bounds. Additionally, the **Hierarchical Speculative Decoding (HSD)** framework stacks multiple models into a tiered structure, allowing each level to verify the one below it. Collectively, these papers provide **mathematical proofs**, **sampling algorithms**, and **hierarchical strategies** designed to maximize token acceptance rates and minimize computational overhead.
Sources:
1)
January 22 2025
Towards Optimal Multi-draft Speculative Decoding
Zhengmian Hu, Tong Zheng, Vignesh Viswanathan, Ziyi Chen, Ryan A. Rossi, Yihan Wu, Dinesh Manocha, Heng Huang.
2)
2024
SpecHub: Provable Acceleration to Multi-Draft Speculative Decoding
Lehigh University, Samsung Research America, University of Maryland
Ryan Sun, Tianyi Zhou, Xun Chen, Lichao Sun
https://aclanthology.org/2024.emnlp-main.1148.pdf.
3)
2024
MULTI-DRAFT SPECULATIVE SAMPLING: CANONICAL DECOMPOSITION AND THEORETICAL LIMITS
Qualcomm AI Research, University of Toronto
Ashish Khisti, M.Reza Ebrahimi, Hassan Dbouk, Arash Behboodi, Roland Memisevic, Christos Louizos
https://arxiv.org/pdf/2410.18234.
4)
2025
HISPEC: HIERARCHICAL SPECULATIVE DECODING FOR LLMS
The University of Texas at Austin
Avinash Kumar, Sujay Sanghavi, Poulami Das
https://arxiv.org/pdf/2510.01336.
5)
2025
Fast Inference via Hierarchical Speculative Decoding
Harvard University, Google Research, Tel Aviv University, Google DeepMind
Clara Mohri, Haim Kaplan, Tal Schuster, Yishay Mansour, Amir Globerson
https://arxiv.org/pdf/2510.19705.