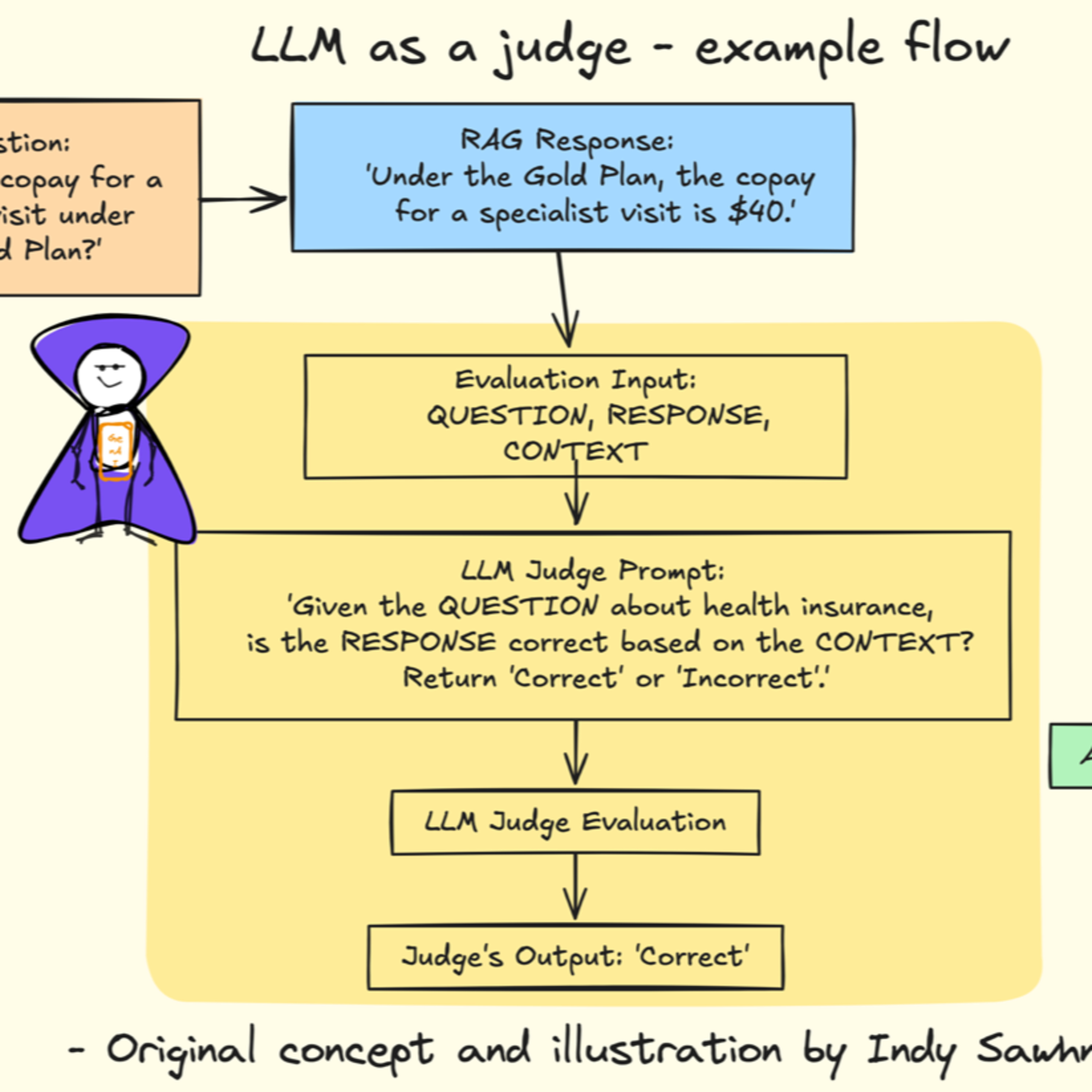
This newsletter discusses how Large Language Models (LLMs) can be used as "judges" to evaluate the accuracy and relevance of responses generated by Retrieval Augmented Generation (RAG) systems. The author, Indy Sawhney, outlines the benefits of using LLMs as judges, including their scalability, consistency, and comprehensive analysis capabilities. He then provides a step-by-step guide for integrating an LLM judge into a RAG workflow and illustrates the process with a healthcare payer example. The author also emphasizes the importance of training LLMs with high-quality data curated by human experts and highlights the need for an evaluation-driven development approach to ensure the accuracy of GenAI applications.