On February 23, 2026, Anthropic published a report titled “Detecting and Preventing Distillation Attacks.” In it, the company disclosed that it had identified coordinated, industrial-scale efforts to extract capabilities from its Claude models. According to the announcement, roughly 24,000 fraudulent accounts generated more than 16 million interactions in patterns consistent with systematic model distillation, using Claude’s outputs to train separate systems designed to approximate its behavior.
No model weights were reported stolen. No source code was leaked.
Instead, the activity relied on scale. Large volumes of prompts were issued, responses were collected, and those responses were used as training data elsewhere.
Anthropic framed the incident not simply as a violation of terms of service, but as a security and strategic risk. Frontier AI systems are expensive to train and heavily engineered for safety. When their outputs are harvested at industrial volume, the resulting replicas may inherit capability without necessarily inheriting safeguards.
The episode highlights a structural feature of modern AI systems. If intelligence can be observed through interaction, it can be measured. And if it can be measured at scale, it can be approximated.
What Is Distillation?
The concept of knowledge distillation was formalized by Geoffrey Hinton and colleagues in 2015 in their landmark paper, Distilling the Knowledge in a Neural Network.
The idea is elegant:
* A large model (teacher) produces probability distributions.
* A smaller model (student) learns to match those outputs.
* The student inherits much of the teacher’s performance.
In its original form, distillation assumes access to internal model signals, specifically logits. Logits are the raw probability scores a model produces before selecting a final answer. They reveal more than just what the model chose. They show how strongly the model considered other possibilities.
Training on those signals allows a smaller model to mimic much of the larger model’s performance, often with fewer parameters and lower computational cost.
Large language models deployed through APIs change that setup. External users do not see logits. They see text.
But text is still informative. Every prompt and response pair reflects how the model behaves. At small scale, those interactions are just conversations. At large scale, they become data.
This is where distillation overlaps with what researchers call model extraction. Instead of learning from internal probabilities, a student model learns from observed behavior. Inputs are recorded. Outputs are collected. A new model is trained to reproduce that mapping.
At its core, a neural network represents a mathematical function. If you can gather enough examples of inputs and outputs, you can train another network to approximate that function.
Alignment Does Not Transfer Cleanly
Modern LLMs undergo layers of safety training:
* Supervised fine-tuning
* Reinforcement Learning from Human Feedback (RLHF)
* Constitutional AI (Anthropic-specific methodology)
Distillation copies outputs.
It does not copy the training process that produced them.
Alignment in frontier models is created through additional optimization steps. These include reinforcement learning from human feedback, rule-based constraints, and safety classifiers that shape how the model responds and when it refuses.
When a student model is trained only on sampled outputs, it learns to reproduce visible behavior. It does not inherit the reward models, policy rules, or optimization objectives that enforced that behavior during training.
The result can be a system that performs similarly under normal conditions but lacks the mechanisms that trigger refusals under dangerous ones.
That difference matters in concrete ways. An aligned frontier model may refuse a request to outline methods for synthesizing a prohibited biological agent, to design a cyberattack against critical infrastructure, to optimize production of a restricted chemical compound, or to generate targeted disinformation strategies aimed at destabilizing an election. Those refusals are not accidental. They are the product of deliberate safety training layered onto the base model.
A distilled replica trained only on observed outputs may reproduce the fluency and technical competence of the original system. It may not reproduce the boundaries.
Who Was Behind It
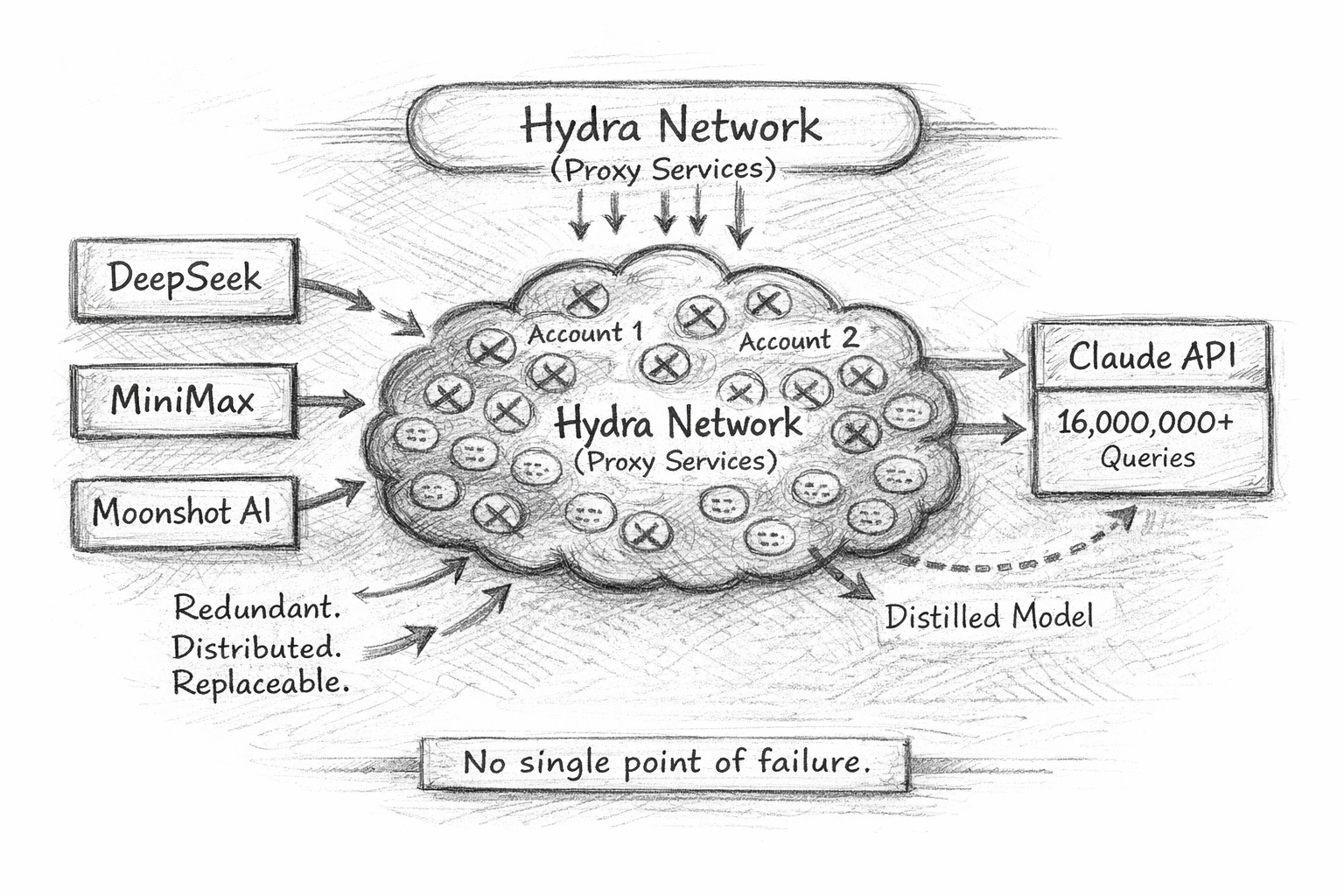
Anthropic attributed the coordinated activity to three Chinese AI laboratories: DeepSeek, MiniMax, and Moonshot AI.
According to the company, the activity was not limited to isolated misuse. It described sustained, large-scale efforts involving tens of thousands of fraudulent accounts and millions of interactions structured in patterns consistent with model distillation.
Anthropic stated that it does not offer commercial access to Claude in China, or to subsidiaries of those companies operating outside the country. The implication was clear: the access had to be routed indirectly.
How It Worked
Anthropic’s report provides unusual detail about the mechanics.
Because Claude is not commercially available in China, the labs allegedly relied on commercial proxy services that resell access to frontier models. These proxy services operate what Anthropic refers to as “hydra cluster” architectures. The term describes sprawling networks of fraudulent accounts designed to distribute traffic across APIs and cloud platforms.
Each account appears independent. Each generates traffic that resembles ordinary usage. When one account is banned, another replaces it.
In one instance cited by Anthropic, a single proxy network managed more than 20,000 fraudulent accounts at the same time. Distillation traffic was blended with unrelated customer requests, making it difficult to isolate suspicious patterns at the account level.
The Economics of Sampled Intelligence
Training a frontier model costs hundreds of millions of dollars in compute, engineering, and data curation.
Querying a model costs only fractions of a cent.
If sufficient capability can be reconstructed through querying, the economics shift dramatically.
Intelligence becomes:
* Expensive to originate
* Cheap to approximate
In classical software, copying binaries constitutes direct duplication. In machine learning, copying behavior produces approximation.
That distinction alters the economics of advantage.
Defensive AI
Anthropic outlined several measures it has implemented in response to large-scale distillation activity.
These include:
* Behavioral anomaly detection designed to identify coordinated or repetitive query patterns.
* Enhanced account verification and monitoring procedures.
* Cross-platform information sharing with cloud providers and industry partners.
The focus is not on preventing individual misuse, but on detecting distributed patterns across large volumes of traffic.
These efforts align with broader research into watermarking and output fingerprinting techniques for large language models. Such approaches aim to make model outputs statistically traceable or to identify systematic extraction attempts over time.
The underlying challenge is structural. When models are deployed through APIs, their behavior becomes observable. Defending against distillation requires monitoring not only access credentials, but usage patterns and statistical regularities across accounts.
This shifts part of AI security from perimeter control to behavioral analysis.
Export Controls in the Age of Query Replication
The United States has imposed export controls on advanced AI chips and high-performance computing hardware. The logic behind these policies is straightforward: access to leading-edge compute enables the training of frontier models. Restrict compute, and you constrain capability.
This framework assumes that capability is primarily a function of hardware access.
Distillation complicates that assumption.
If a laboratory cannot train a frontier model from scratch because of hardware restrictions, but can approximate aspects of it by sampling a deployed system, then capability can flow through interaction rather than through silicon.
Export controls limit chips. They do not limit API outputs.
This does not render hardware controls irrelevant. Training a frontier system still requires massive compute investment. But it introduces an alternative pathway for capability acquisition, one that operates through distributed access and statistical reconstruction rather than direct training.
The policy question becomes more precise. Are controls aimed at infrastructure, at model weights, or at behavior? And if behavior is globally accessible through commercial APIs, what does effective containment mean in practice?
Distillation does not eliminate asymmetries in compute. It narrows them.
That narrowing is where the strategic tension lies.
What This Means for Control and ContainmentDistillation exposes a structural limit in how control over AI systems is currently conceived.
Much of today’s policy framework assumes that capability can be contained by controlling hardware, model weights, or corporate access. Export controls restrict advanced chips. Companies restrict direct access to frontier models. Contracts govern usage.
Distillation operates in a different domain. It does not require access to weights. It does not require possession of training pipelines. It requires sustained interaction.
When intelligence is deployed through APIs, its behavior becomes observable. When behavior can be observed at scale, it can be approximated. That approximation may not reproduce the original system in full, but it may be sufficient for many operational purposes.
This creates tension between deployment and containment. Open access accelerates adoption and revenue. It also increases exposure.
Three responses are emerging:
One response is tighter control. Companies could restrict access more aggressively, strengthen identity verification, and monitor usage patterns more closely. In this model, frontier systems become more centralized and more tightly guarded.
Another response is to accept that some diffusion is inevitable. If capabilities can be approximated through sampling, competitive advantage may shift away from raw model performance and toward distribution, integration, proprietary data, and execution speed.
A third response focuses on detection rather than restriction. Techniques such as watermarking, output fingerprinting, and auditable logging aim to make large-scale extraction easier to identify and trace.
None of these approaches fully remove the underlying tension. When a system is accessible through interaction, parts of its behavior can be observed and learned from.
Containment becomes less about absolute prevention and more about limiting scale and speed.
The practical question for policymakers and companies is not whether replication can occur, but how much, how fast, and with what consequences.
Consequences
The consequences operate on several levels.
At the company level, large-scale distillation erodes the economic return on frontier training investments. If a model that costs hundreds of millions of dollars to develop can be approximated through sustained querying, the competitive moat narrows. Revenue models based on controlled access become harder to defend.
At the security level, replication without full alignment introduces risk. A distilled system that mirrors capability but lacks robust refusal mechanisms may respond differently to harmful prompts. The safeguards embedded through additional training stages do not automatically transfer through behavioral sampling.
At the geopolitical level, distillation weakens the assumptions underlying hardware-based export controls. If capability can be partially reconstructed through distributed access to deployed systems, then compute restrictions alone may not fully determine who can field advanced AI capabilities.
For the labs involved, the immediate consequences may include contractual disputes, restricted access, and reputational impact. For the broader ecosystem, the consequences are structural. Distillation at scale forces companies and governments to rethink how advantage, control, and safety are maintained once intelligence is deployed as a service.
The question is not whether this specific incident changes the balance of power overnight.
It is whether repeated incidents like it gradually reshape the economics and governance of frontier AI.
Thanks for reading Deep Learning With The Wolf ! This post is public so feel free to share it.
Key Terms:
Knowledge Distillation: Training a smaller model to mimic a larger model’s outputs.
Logits: Raw probability scores a model produces before selecting an output.
Model Extraction: Using API access to reconstruct a model’s behavior.
RLHF (Reinforcement Learning from Human Feedback): A training method that aligns models with human preferences.
Constitutional AI: Anthropic’s approach to alignment using explicit rule-based self-critique.
Sample Complexity: The number of examples needed to approximate a function well.
Additional Resources for Inquisitive Minds
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the Knowledge in a Neural Network.” arXiv, 2015.
Tramer, Florian, et al. “Stealing Machine Learning Models via Prediction APIs.” USENIX Security, 2016.
Bai, Yuntao, et al. “Constitutional AI.” arXiv, 2022.
Kirchenbauer, John, et al. “A Watermark for Large Language Models.” arXiv, 2023.
Anthropic. “Detecting and Preventing Distillation Attacks.” 2026.
U.S. Bureau of Industry and Security. AI Export Controls. 2023.
FAQs
Is distillation illegal? No. It’s a standard ML technique. Unauthorized extraction may violate terms or IP law.
Does distillation perfectly copy a model? No. It approximates behavior.
Can safety alignment transfer through distillation? Not reliably or completely.
Is this primarily a security issue or economic issue? Both.
Can model extraction be fully prevented? Likely not fully — only mitigated.
#AISafety #Distillation