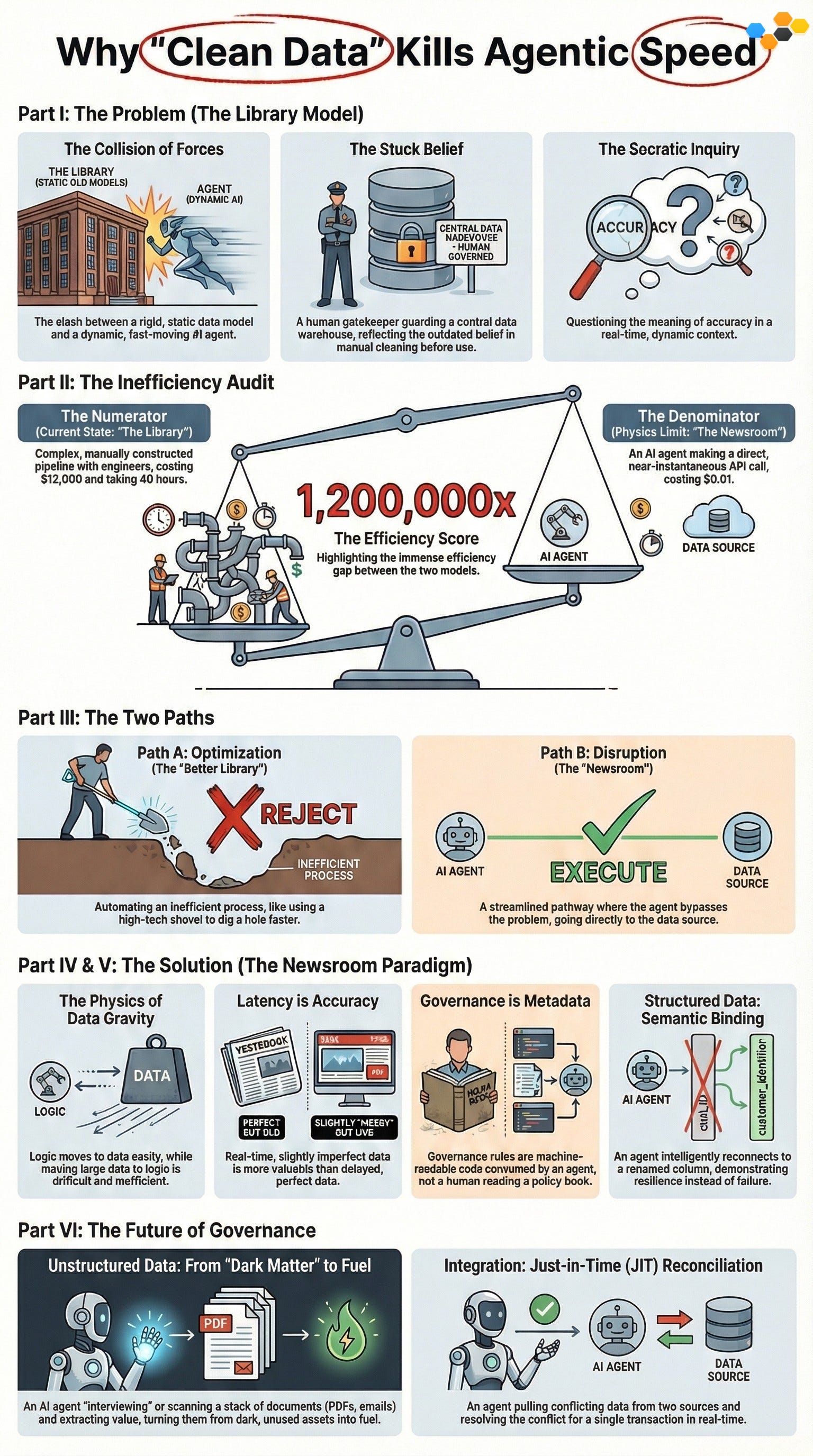
Companies are currently failing by forcing fast AI agents to use slow, centralized data warehouses, which creates a massive bottleneck. This traditional approach costs roughly $12,000 per data feed, making it 1.2 million times less efficient than letting an agent query data directly for just one penny. To fix this, businesses must switch to a "Newsroom" model where agents access raw data at the source instead of moving it. This method allows agents to clean data instantly when needed, drastically reducing costs and delays
PART I: THE DECONSTRUCTION (THE LIBRARY MODEL)
The Collision of Forces
We’re witnessing a violent collision between two opposing forces in the enterprise. On one side, we have the “Library” model of data management—static, centralized, and governed by human committees. On the other, we have Agentic AI—dynamic, distributed, and demanding real-time context. The industry’s trying to force the latter into the former, and it’s failing.
This failure isn’t technical; it’s philosophical. It stems from a single, deep-seated misconception that we need to excise before we can build anything new.
The Stuck Belief
“Data Governance is a protective gatekeeping function that requires centralization, rigid schemas, and human oversight to ensure accuracy before consumption.”
The Socratic Inquiry
To dismantle this, we need to apply the Scalpel. We can’t just accept “Accuracy” as a vague good; we have to interrogate it.
* Clarification: What exactly do we mean by “accuracy” in a context where data changes faster than the cleaning cycle? If an agent needs a stock price now to execute a trade, is a “clean” value from yesterday’s batch process accurate? Or is it just “precisely wrong”?
* Challenging Assumptions: Why do we assume data needs to be moved to a central warehouse to be useful? Is this a requirement of physics (like gravity), or is it a legacy artifact of 1990s compute limitations?
* Evidence & Reasons: What evidence supports the belief that human-curated schemas reduce hallucination better than semantic injection at inference time? Have we tested this, or is it just how we’ve always done it?
* Implications: If we stick to “The Library,” what breaks? The answer is simple: The Agent. It will either wait for the data (Latency Failure) or it will bypass IT entirely to get what it needs (Security Failure).
PART II: THE EFFICIENCY DELTA
The Economic Absurdity
We can’t argue with sentiment; we have to argue with math. We need to calculate the ID10T Index (Inefficiency Delta in Operational Transformation) for the simple act of integrating a new data feed for an AI agent.
The Numerator (Current State: “The Library”)
In the traditional model, integrating a new source requires building a “Data Pipeline.” This is a manual construction project.
* Process: A Data Engineer writes custom Python/SQL extractors. A Data Steward defines the schema and access policies. A QA team validates the data.
* Labor: We’re paying L3 Professionals (Engineers) at $300/hr and L2 Skilled Trades (Stewards) at $75/hr.
* Time: Industry average is roughly 40 operational hours to build, test, and deploy a robust feed.
* The Cost: 40 hours × ~$300/hr (blended rate) = $12,000 per feed.
The Denominator (Physics Limit: “The Newsroom”)
Now, look at the physics limit. What’s the theoretical minimum cost for an agent to get that same data?
* Process: The agent authenticates via API. It reads the schema documentation (or infers it from the JSON response). It performs Just-in-Time (JIT) reconciliation for the specific query.
* Labor: 0 Human Hours.
* Compute: 100 tokens of input context + 1 API call.
* Physics Floor: The “Bits Floor” (Agentic Limit).
* The Cost: $0.01 per interaction.
The Efficiency Score
$12,000 divided by $0.01 equals 1,200,000.
The current approach is 1.2 million times less efficient than the theoretical minimum. We aren’t just inefficient; we’re practicing digital archaeology. We’re spending professional-grade capital to build permanent infrastructure for transient data needs.
PART III: THE PATH CHOICE (OPTIMIZATION VS. DISRUPTION)
We’re staring at a 1.2 million-fold gap. We have two ways to close it.
Path A: Optimization (The “Better Library”)
This is the seductive trap.
* The Strategy: Use Generative AI to “code faster.” We build “Co-pilots for Data Engineers” that automate the writing of ETL pipelines and SQL scripts.
* The Result: We reduce the time to build a pipeline from 40 hours to 4 hours. We lower the cost from $12,000 to $1,200.
* The Fatal Flaw: This violates Command 5 of the First Principles Protocol: “Do not automate an inefficient process.” By choosing Path A, we’re just digging the grave faster. We’re still moving heavy data to the logic (violating Data Gravity). We’re still maintaining rigid schemas that break when a column changes. We’ve optimized a process that shouldn’t exist.
* Verdict: REJECT.
Path B: Disruption (The “Newsroom”)
This is the necessary pivot.
* The Strategy: Eliminate the pipeline entirely. Move the logic (The Agent) to the data (The Source).
* The Execution: We build a “Semantic Control Plane” that allows agents to query raw APIs directly, utilizing Just-in-Time governance.
* The Result: We hit the physics limit of $0.01 per interaction.
* Verdict: EXECUTE.
PART IV: THE RECONSTRUCTION (THE SEMANTIC CONTROL PLANE)
To execute Path B, we need to rebuild our architecture based on physics, not tradition. We rely on these Foundational Axioms:
The Physics of Data Gravity
Logic Travels, Data Stays.
Data is heavy (Terabytes). Logic is light (Kilobytes). It’s always cheaper and faster to send the query to the data than to copy the data to a warehouse. We’re moving to a Zero-Copy architecture where the agent visits the data where it lives.
Latency is Accuracy
Data that’s “clean” but 24 hours old is functionally incorrect for an autonomous agent. Real-time access to “messy” data is superior to delayed access to “perfect” data, provided the agent has the intelligence to filter the noise.
Governance is Metadata
We stop writing governance policies in PDF documents. Governance rules need to be machine-readable instructions—a “Semantic Constitution”—that the agent consumes at runtime. This isn’t a gate; it’s a lens.
PART V: THE EXECUTION (THE NEWSROOM PARADIGM)
We’re shifting from “The Library” (Hoarding) to “The Newsroom” (Reporting). Here’s how the new stack functions across the three critical pillars of data.
Structured Data: Semantic Binding
In the Library, if a Salesforce admin changes cust_ID to customer_identifier, the SQL pipeline breaks. Humans rush to fix it. This is the Fragility Loop.
In the Newsroom, we use Semantic Binding. We don’t tell the agent “Look at Column A.” We tell the agent “Look for the Unique Customer Identifier.” The agent scans the schema at runtime, infers that customer_identifier is the target, and writes its own query. We’ve replaced Explicit Reference (brittle) with Semantic Inference (resilient). The ID10T cost of maintenance drops to zero.
Unstructured Data: From “Dark Matter” to Fuel
80% of enterprise data is unstructured (PDFs, Emails, Slack). In the Library, this is “Dark Matter”—invisible to SQL. Extracting value requires an L3 Professional ($300/hr) to read the documents.
In the Newsroom, this is our primary fuel.
* Manual Review: Reading a 50-page contract takes 1 hour. Cost: $300.
* Agentic Review: An LLM with a 128k context window ingests the PDF in seconds. Cost: $0.05.
This 6,000x cost reduction flips the economics. We don’t need to structure the unstructured; we just need to give the agent RAG (Retrieval-Augmented Generation) access to “interview” the documents.
Integration: Just-in-Time (JIT) Reconciliation
The biggest objection to Zero-Copy is: “If we don’t centralize it, we can’t clean it.”
This is false. We don’t need all the data to be clean all the time. We need specific data points to be clean right now.
Instead of a nightly batch job that scrubs 10 million records (Just-in-Case), the Agent performs JIT Reconciliation. If it pulls an address from CRM and an address from Billing, and they conflict, the agent resolves that specific conflict in real-time using the Semantic Constitution. We pay for the compute to clean only what we consume.
PART VI: CONCLUSION & THE FUTURE (SELF-HEALING GOVERNANCE)
The Privacy Pivot: Context-Aware Masking
We’re also solving the “Third Rail”: PII. Instead of binary Access Control (You see it or you don’t), we use Context-Aware Masking. We allow the agent to “see” the Social Security Number to perform a verification, but the Semantic Constitution strictly prohibits writing that SSN to the logs or memory. We govern observation, not just access.
Self-Healing Governance
The ultimate destination isn’t just an agent that reads data; it’s an agent that fixes it. When our “Journalist” agent finds a discrepancy, it doesn’t just error out. It generates a Governance Proposal—a suggestion to update the semantic map or flag a dirty record. The Data Stewards stop being janitors and start being Editors, approving the fixes that the agents propose.
We’re done building $12,000 pipelines for $0.01 questions. The Library is closed. The Newsroom is open.
If you find my writing thought-provoking, please give it a thumbs up and/or share it. If you think I might be interesting to work with, here’s my contact information (my availability is limited):Book an appointment: https://pjtbd.com/book-mike
Email me: mike@pjtbd.com
Call me: +1 678-824-2789
Join the community: https://pjtbd.com/join
Follow me on 𝕏: https://x.com/mikeboysen
Articles - jtbd.one - De-Risk Your Next Big Idea
New Masterclass: Principle to Priority
Q: Does your innovation advisor provide a 6-figure pre-analysis before delivering the 6-figure proposal?