坐飞机去圣迭戈参加 NeurIPS 2025,结果一上飞机整个人傻眼: 机舱里至少30%的人,手机、iPad、MacBook 打开的全部是同一个PDF——DeepSeek 昨天刚放出来的 V3.2 技术报告这份报告发布时机完美,正好赶上NeurIPS 2025(神经信息处理系统大会)前夕(会议在圣迭戈举行)
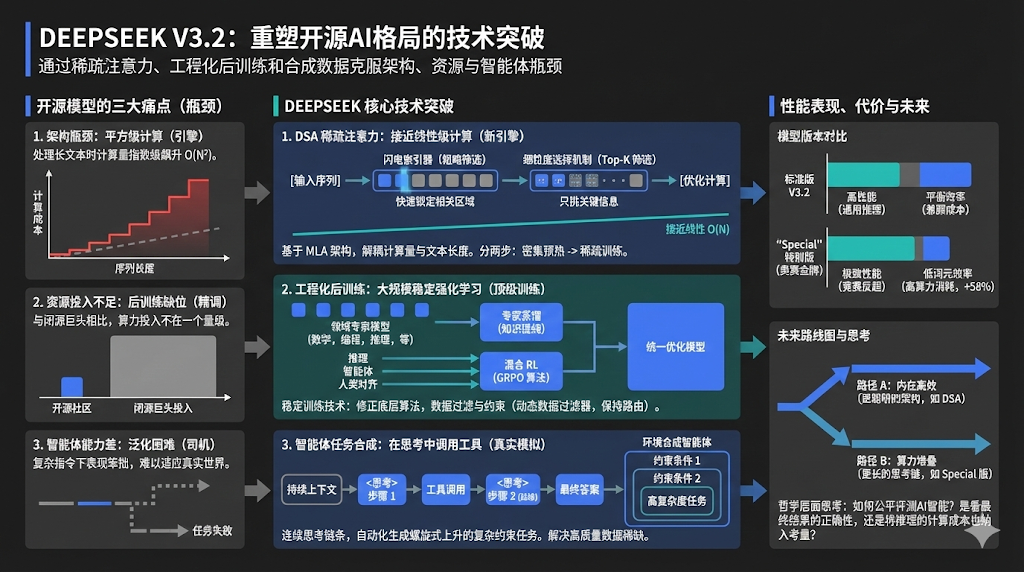
DeepSeek V3.2 技术报告分析,帮你理解3.2 是如何通过“换引擎”与“魔鬼特训”,在国际奥数金牌级任务上追平闭源巨头 Gemini 3.0 Pro。
一:换引擎:DSA 稀疏注意力架构
- 打破“油耗”瓶颈:传统注意力机制随文本变长计算量呈平方级暴涨,DSA(DeepSeek 稀疏注意力)架构将其降至接近线性,大幅提升长文本处理效率。
- 图书馆索引比喻:引入“闪电索引器”(一种快速筛选核心信息的组件)锁定相关书架,而非逐页翻阅全库,实现极低成本的信息检索。
- 模拟器训练法:采用“密集预热”策略(先冻结主体参数只练索引器),再转入全面解冻的实战训练,完美解决了新旧架构的过渡难题。
二:练车手:专家蒸馏与 GRPO 算法
- 专家分治策略:训练 6 个垂直领域的“单项冠军”模型(专家蒸馏),生成高质量合成数据反哺通用模型,实现知识提纯。
- GRPO 混合训练:利用 GRPO(一种能兼顾多任务平衡的强化学习算法)将推理、智能体与人类对齐任务一锅炖,有效防止模型“学了编程忘数学”。
- 部门路由锁定:在 MoE(混合专家模型)训练中强制保持专家选择的一致性,避免因模型自我进化导致“昨天选张三、今天选李四”的混乱。
三:强路感:智能体思维与数据合成
- 保留草稿纸:在调用工具时保留完整的 CoT(思维链,即推理过程的中间步骤)上下文,解决了以往模型“每用一次工具就清空记忆”的断层痛点。
- AI 互搏出题:构建“环境合成智能体”(专门负责出难题的 AI),通过层层叠加约束条件(如限时、限价的旅行规划),自动化生成高难度数据。
- 性能代价论:Special 版模型通过消耗更多词元进行“长思考”(串行计算逻辑),以牺牲推理速度为代价,换取了极致的准确率。
