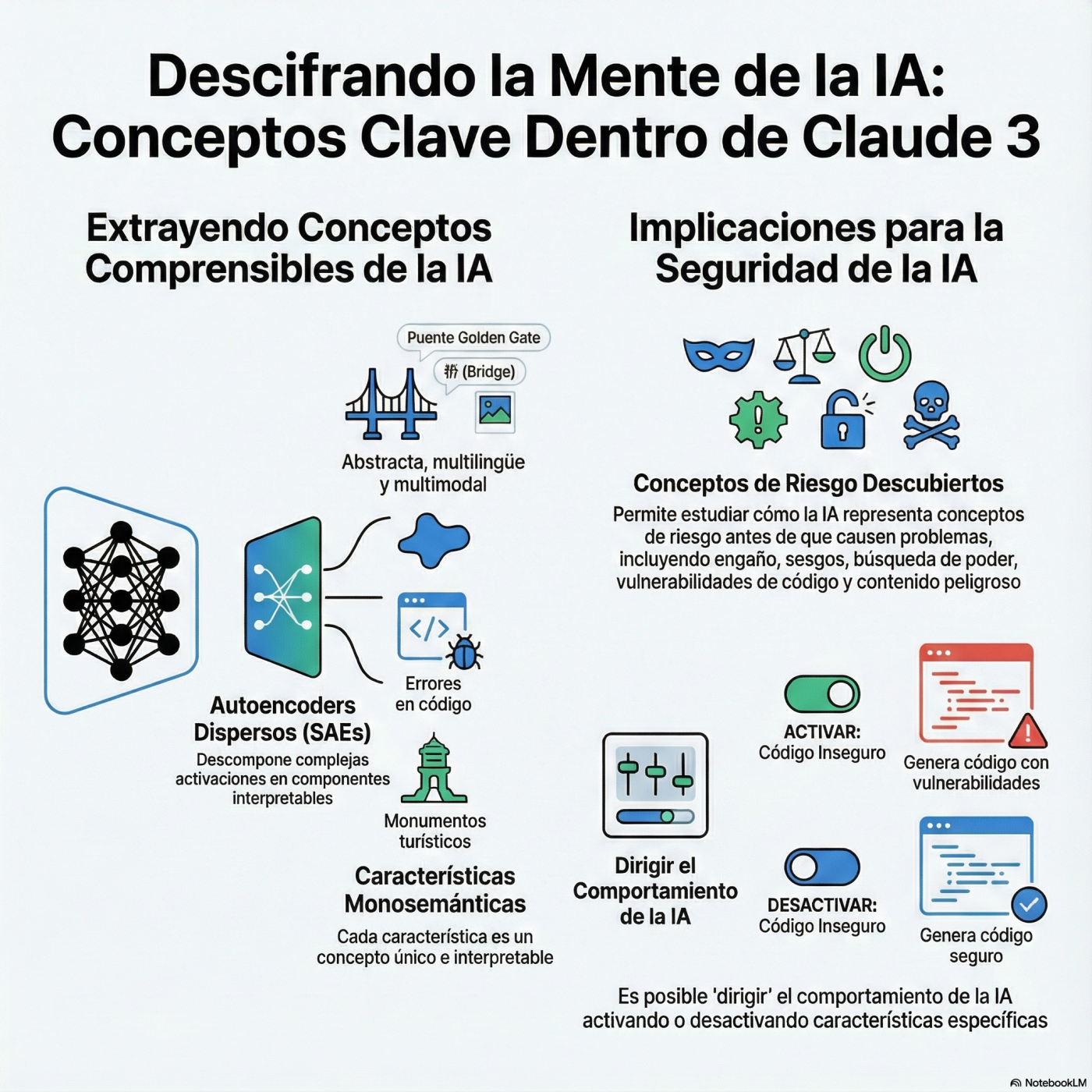
¿Alguna vez te has preguntado qué “piensa” realmente una IA antes de responderte? 🧠 En este episodio nos adentramos en la fascinante investigación de Anthropic sobre Claude 3 Sonnet, donde han logrado abrir la “caja negra” de las redes neuronales a gran escala. 🔓 Utilizando una técnica llamada Sparse Autoencoders, los investigadores han extraído millones de características interpretables, creando un mapa detallado de la mente del modelo. Descubriremos cómo han identificado neuronas específicas para conceptos tan variados como el Golden Gate Bridge 🌁, errores de programación sutiles 💻, e incluso abstracciones complejas como la ironía o la poesía. 🤯
Pero lo más sorprendente no es solo ver estas características, sino controlarlas. 🎛️ Analizaremos cómo este avance permite “sintonizar” el comportamiento del modelo, amplificando o suprimiendo rasgos vinculados a la adulación, el engaño 🤥 o el conocimiento peligroso sobre armas biológicas ☣️. Es un paso crucial para la seguridad de la IA, permitiéndonos entender y mitigar riesgos ocultos antes de que ocurran. 🛡️ Dale al play para explorar cómo la interpretabilidad mecánica está cambiando las reglas del juego y qué sucede realmente cuando obligas a una IA a obsesionarse con un puente. 🌉✨
Fuentes relevantes:
• Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet