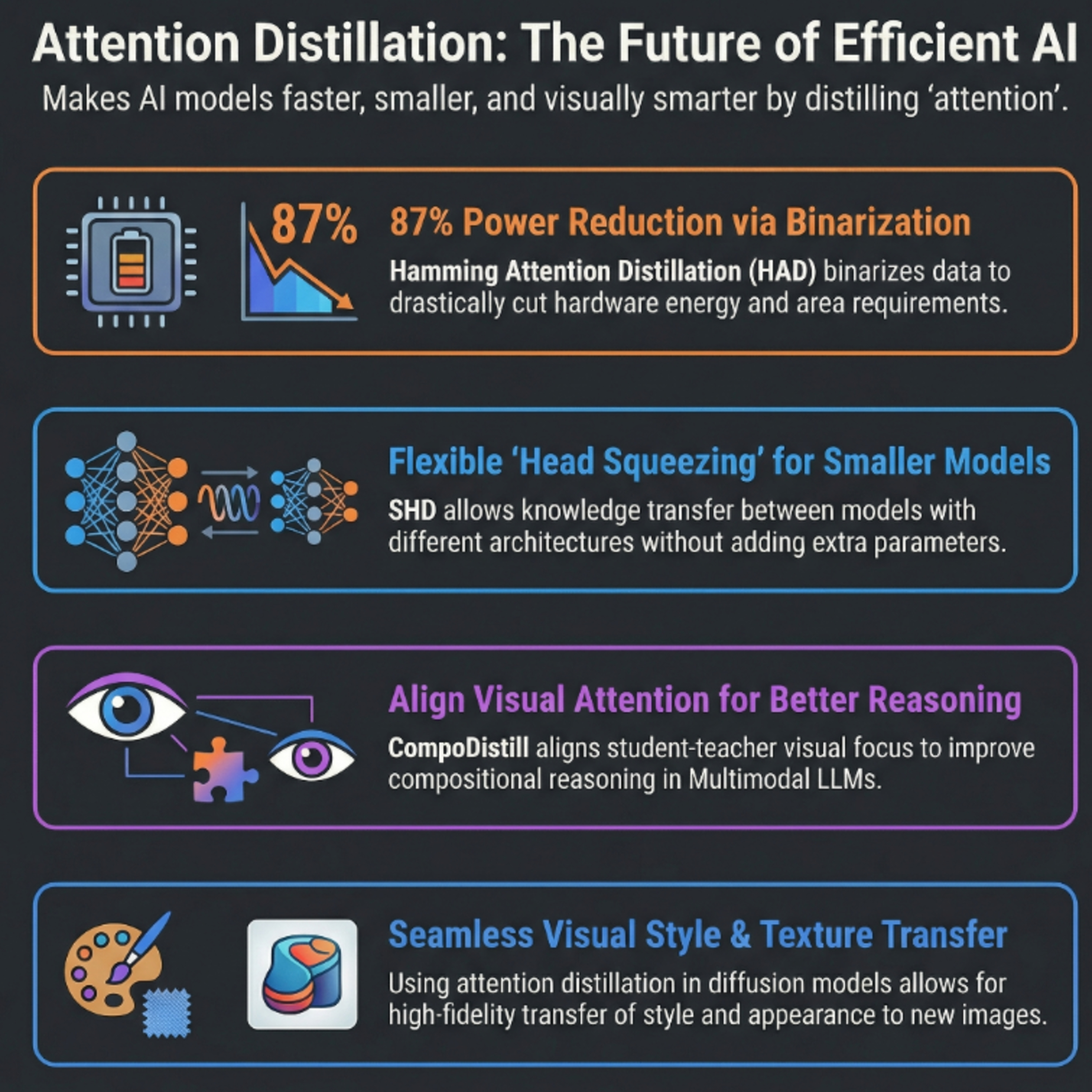
Recent research advances attention distillation to optimize transformers. HAD binarizes keys/queries for efficiency, while SHD aligns varying head counts. CompoDistill improves multimodal reasoning via visual alignment, and new losses transfer visual characteristics in diffusion models.
Sources:
1)
February 3 2025
Hamming Attention Distillation: Binarizing Keys and Queries for Efficient Long-Context Transformers
Mark Horton, Tergel Molom-Ochir, Peter Liu, Bhavna Gopal, Chiyue Wei, Cong Guo, Brady Taylor, Deliang Fan, Shan X. Wang, Hai Li, Yiran Chen
https://doi.org/10.48550/arXiv.2502.01770
2)
February 11 2025
Optimizing Knowledge Distillation in Transformers: Enabling Multi-Head Attention without Alignment Barriers
Zhaodong Bing, Linze Li, Jiajun Liang
https://doi.org/10.48550/arXiv.2502.07436
3)
February 27 2025
Attention Distillation: A Unified Approach to Visual Characteristics Transfer
Yang Zhou, Xu Gao, Zichong Chen, Hui Huang
https://doi.org/10.48550/arXiv.2502.20235
4)
October 14 2025
CompoDistill: Attention Distillation for Compositional Reasoning in Multimodal LLMs
Jiwan Kim, Kibum Kim, Sangwoo Seo, Chanyoung Park
https://doi.org/10.48550/arXiv.2510.12184