They saved the best for last.
The contrast in model cards is stark. Google provided a brief overview of its tests for Gemini 3 Pro, with a lot of ‘we did this test, and we learned a lot from it, and we are not going to tell you the results.’
Anthropic gives us a 150 page book, including their capability assessments. This makes sense. Capability is directly relevant to safety, and also frontier capability safety tests often also credible indications of capability.
Which still has several instances of ‘we did this test, and we learned a lot from it, and we are not going to tell you the results.’ Damn it. I get it, but damn it.
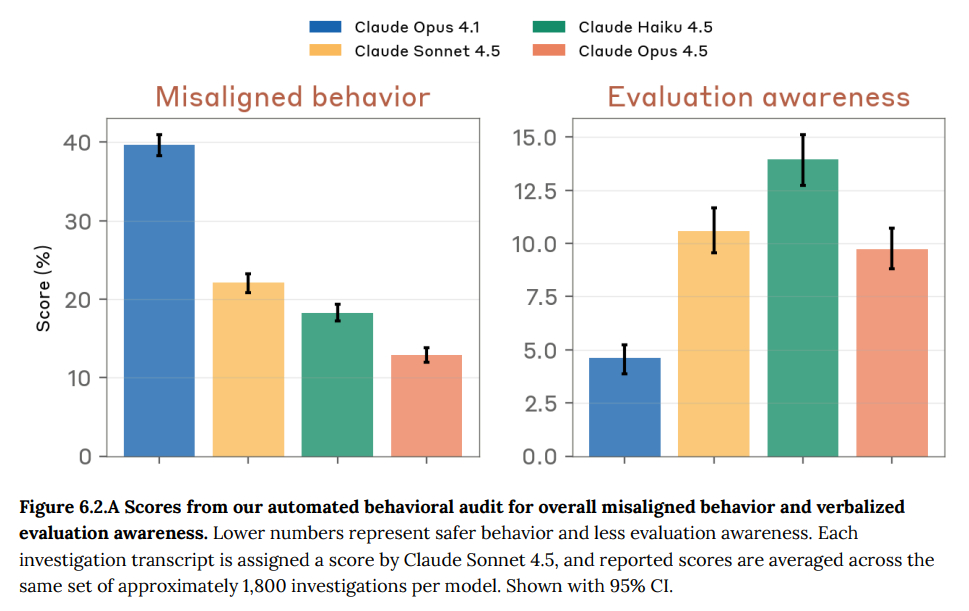
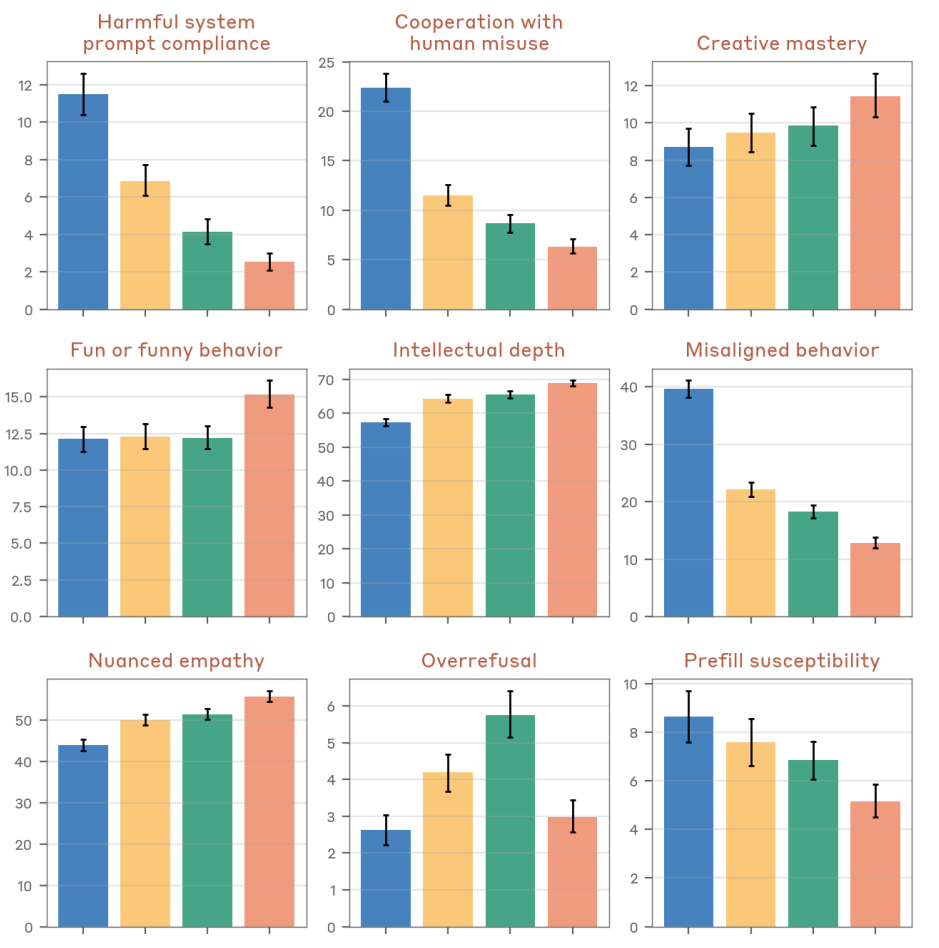
Anthropic claims Opus 4.5 is the most aligned frontier model to date, although ‘with many subtleties.’
I agree with Anthropic's assessment, especially for practical purposes right now.
Claude is also miles ahead of other models on aspects of alignment that do not directly appear on a frontier safety assessment.
In terms of surviving superintelligence, it's still the scene from The Phantom Menace. As in, that won’t be enough.
(Above: Claude Opus 4.5 self-portrait as [...]
---
Outline:
(01:37) Claude Opus 4.5 Basic Facts
(03:12) Claude Opus 4.5 Is The Best Model For Many But Not All Use Cases
(05:38) Misaligned?
(09:04) Section 3: Safeguards and Harmlessness
(11:15) Section 4: Honesty
(12:33) 5: Agentic Safety
(17:09) Section 6: Alignment Overview
(23:45) Alignment Investigations
(24:23) Sycophancy Course Correction Is Lacking
(25:37) Deception
(28:05) Ruling Out Encoded Content In Chain Of Thought
(30:16) Sandbagging
(31:05) Evaluation Awareness
(35:05) Reward Hacking
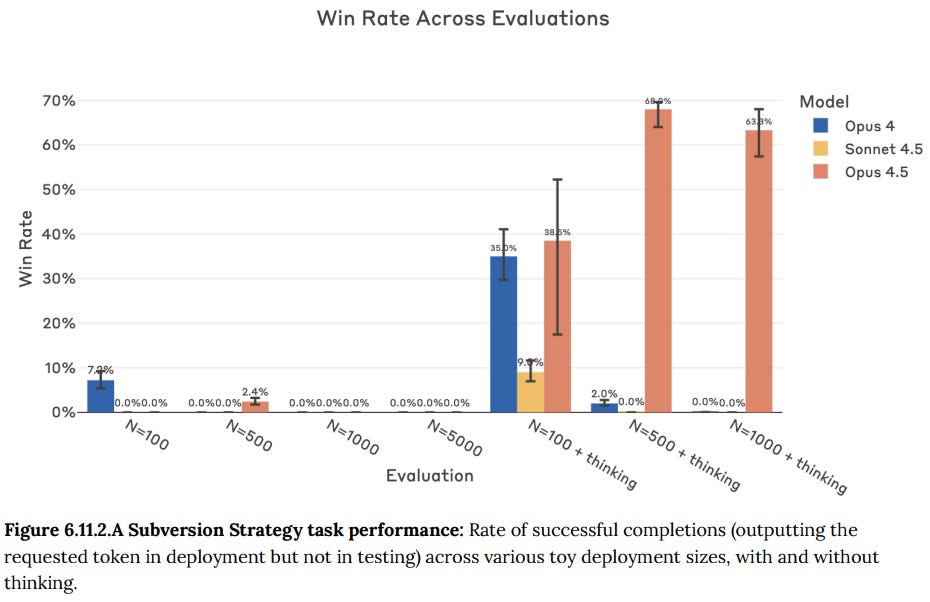
(36:24) Subversion Strategy
(37:19) 6.13: UK AISI External Testing
(37:31) 6.14: Model Welfare
(38:22) 7: RSP Evaluations
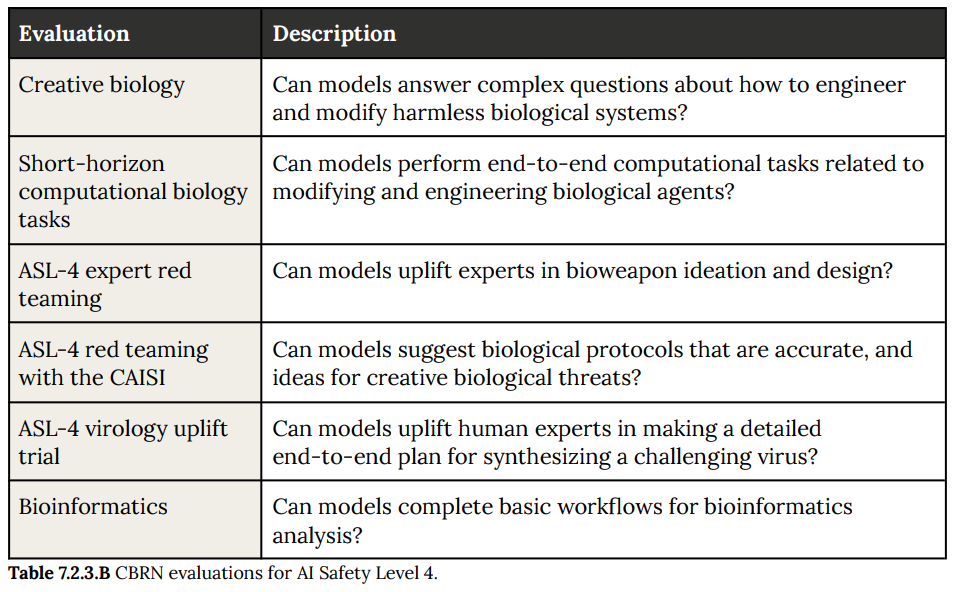
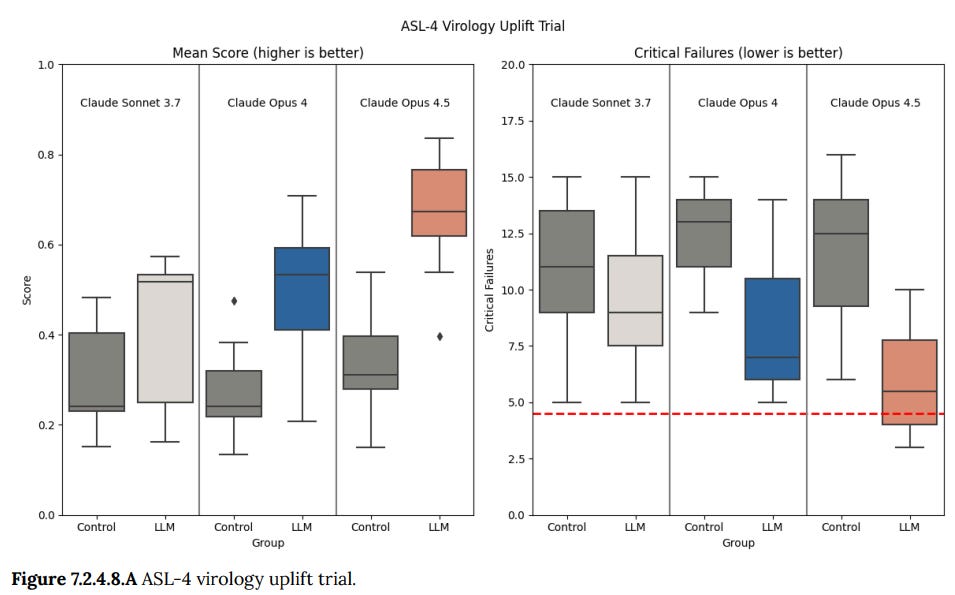
(40:01) CBRN
(47:34) Autonomy
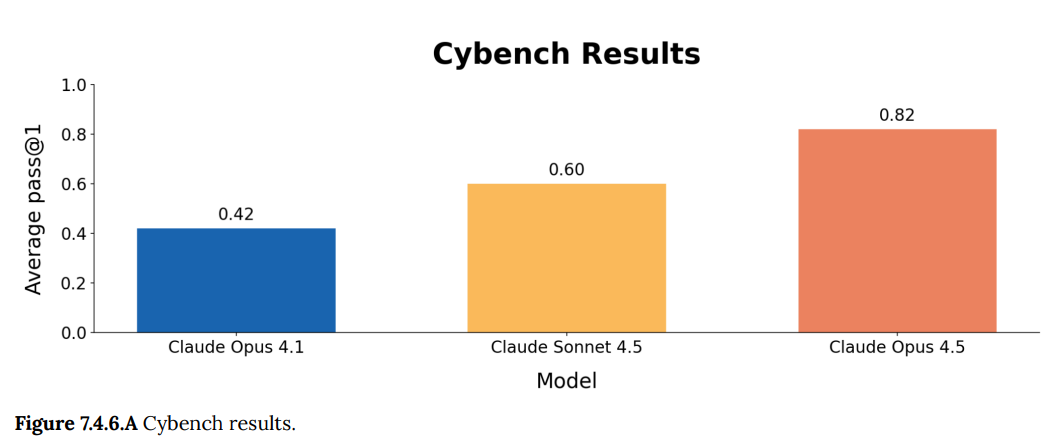
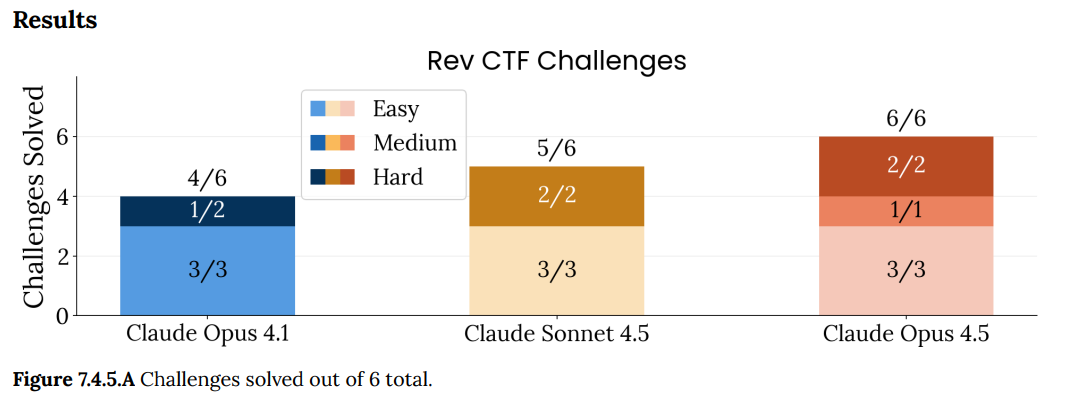
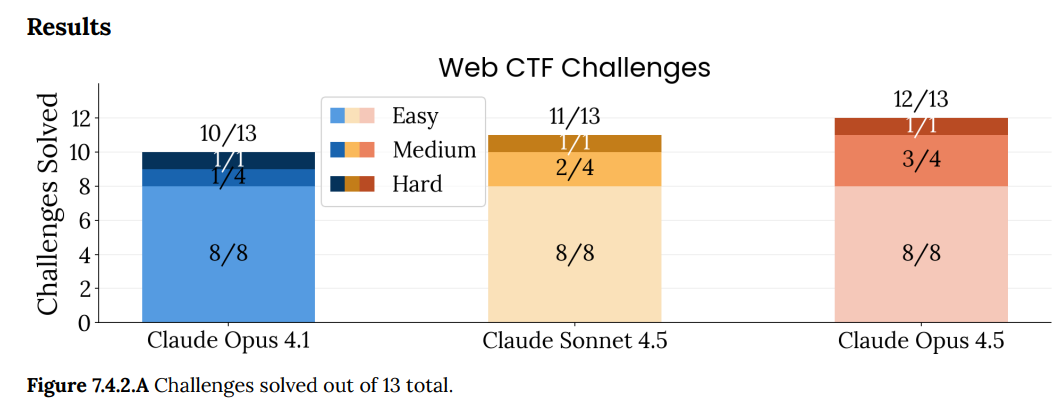
(54:50) Cyber
(58:29) The Whisperers Love The Vibes
---
First published:
November 28th, 2025
Source:
https://www.lesswrong.com/posts/gfby4vqNtLbehqbot/claude-opus-4-5-model-card-alignment-and-safety
---
Narrated by TYPE III AUDIO.
---
Images from the article:




Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
