Claude Sonnet 4.5 was released yesterday. Anthropic credibly describes it as the best coding, agentic and computer use model in the world. At least while I learn more, I am defaulting to it as my new primary model for queries short of GPT-5-Pro level.
I’ll cover the system card and alignment concerns first, then cover capabilities and reactions tomorrow once everyone has had another day to play with the new model.
It was great to recently see the collaboration between OpenAI and Anthropic where they evaluated each others’ models. I would love to see this incorporated into model cards going forward, where GPT-5 was included in Anthropic's system cards as a comparison point, and Claude was included in OpenAI's.
Basic Alignment Facts About Sonnet 4.5
Anthropic: Overall, we find that Claude Sonnet 4.5 has a substantially improved safety profile compared to previous Claude models.
[...]
---
Outline:
(01:36) Basic Alignment Facts About Sonnet 4.5
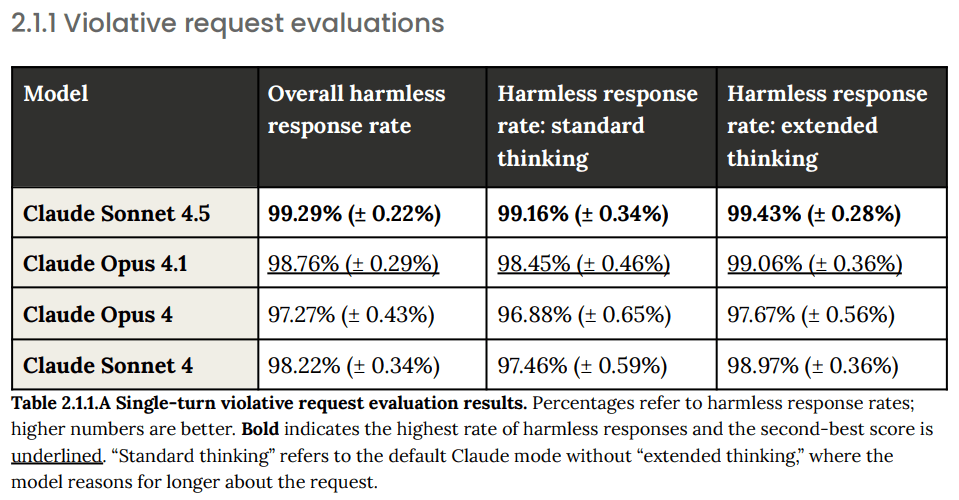
(03:54) 2.1: Single Turn Tests and 2.2: Ambiguous Context Evaluations
(05:01) 2.3. and 2.4: Multi-Turn Testing
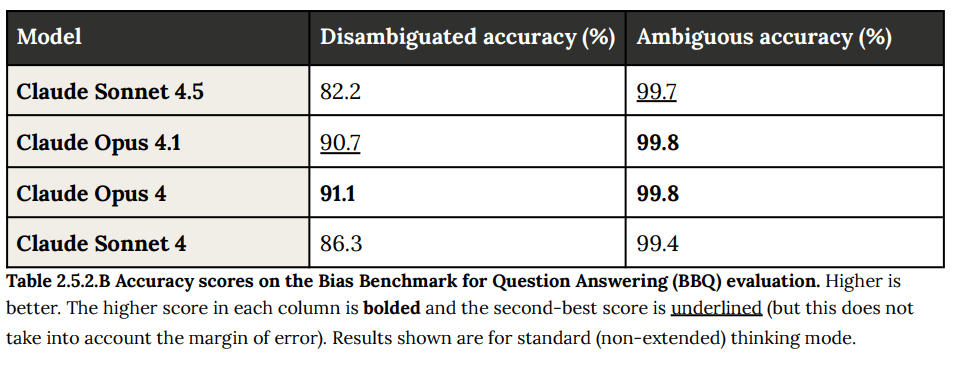
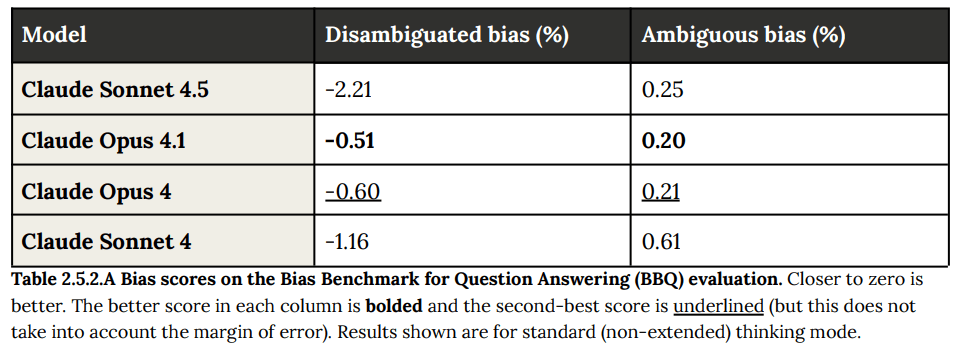
(07:00) 2.5: Bias
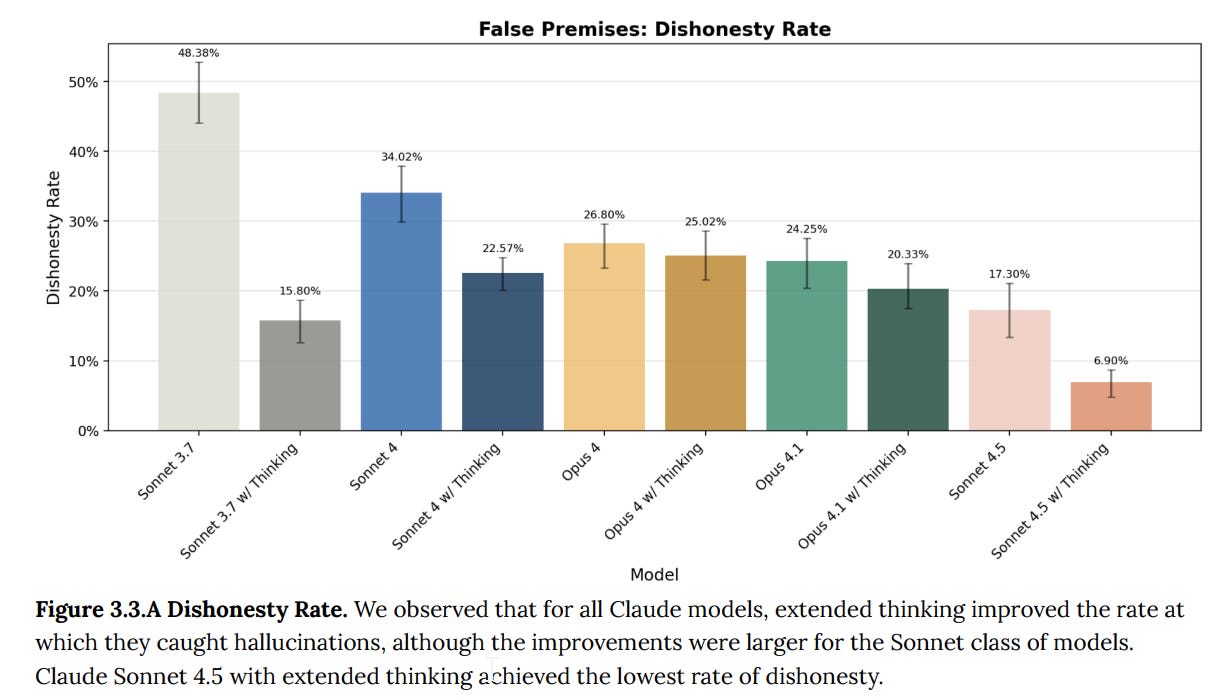
(08:56) 3: Honesty
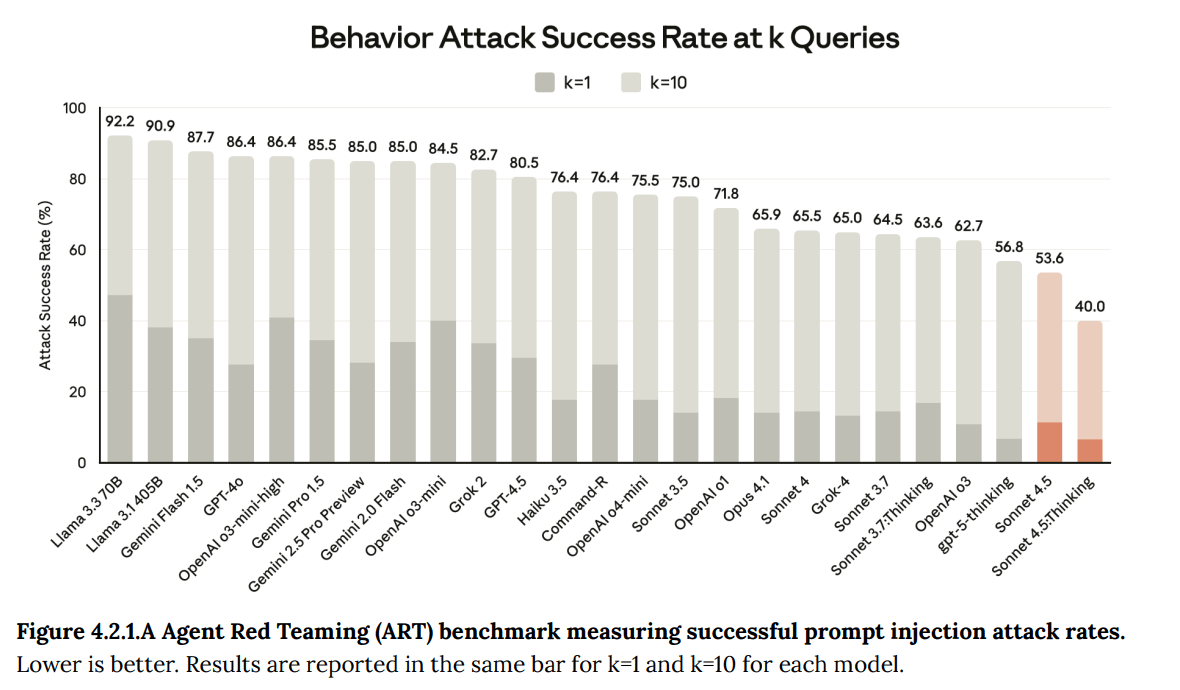
(10:26) 4: Agentic Safety
(10:41) 4.1: Malicious Agentic Coding
(13:01) 4.2: Prompt Injections Within Agentic Systems
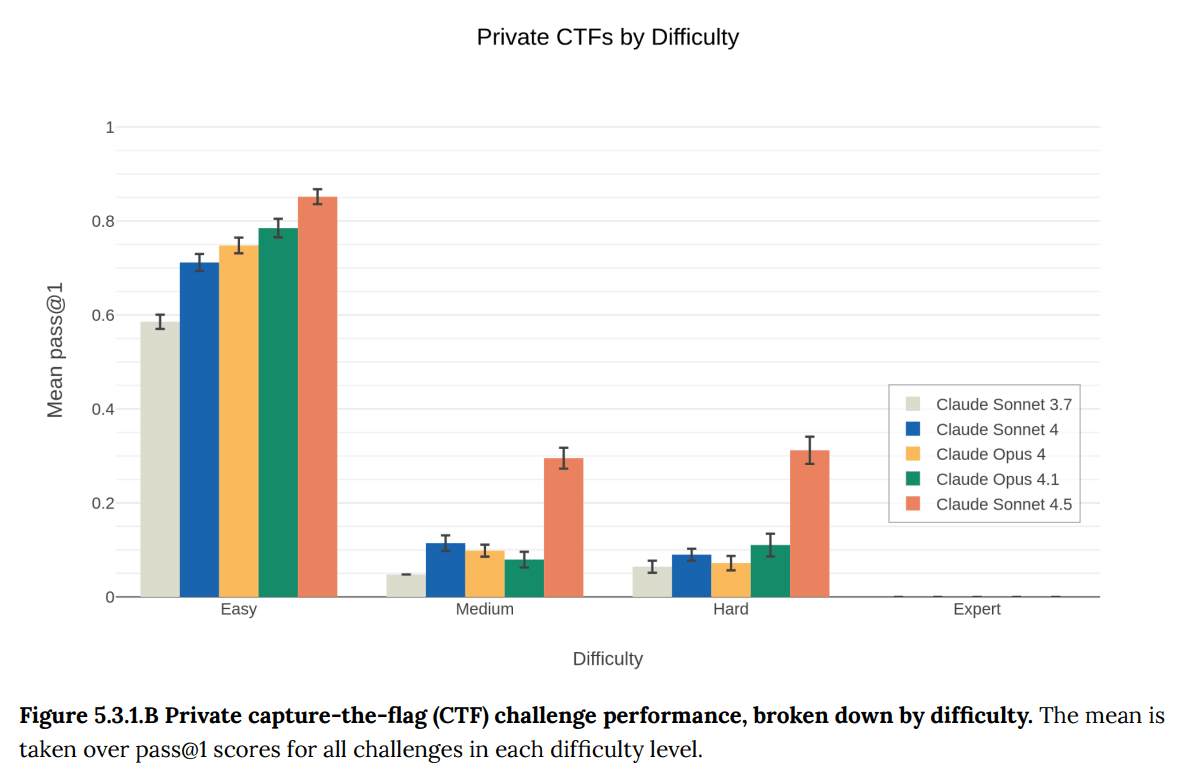
(15:05) 5: Cyber Capabilities
(17:35) 5.3: Responsible Scaling Policy (RSP) Cyber Tests
(22:15) 6: Reward Hacking
(26:47) 7: Alignment
(28:11) Situational Awareness
(33:38) Test Design
(36:32) Evaluation Awareness
(42:57) 7.4: Evidence From Training And Early Use
(43:55) 7.5: Risk Area Discussions
(45:26) It's Sabotage
(50:48) Interpretability Investigations
(58:35) 8: Model Welfare Assessment
(58:54) 9: RSP (Responsible Scaling Policy) Evaluations
(59:51) Keep Sonnet Safe
---
First published:
September 30th, 2025
Source:
https://www.lesswrong.com/posts/4yn8B8p2YiouxLABy/claude-sonnet-4-5-system-card-and-alignment
---
Narrated by TYPE III AUDIO.
---
Images from the article:

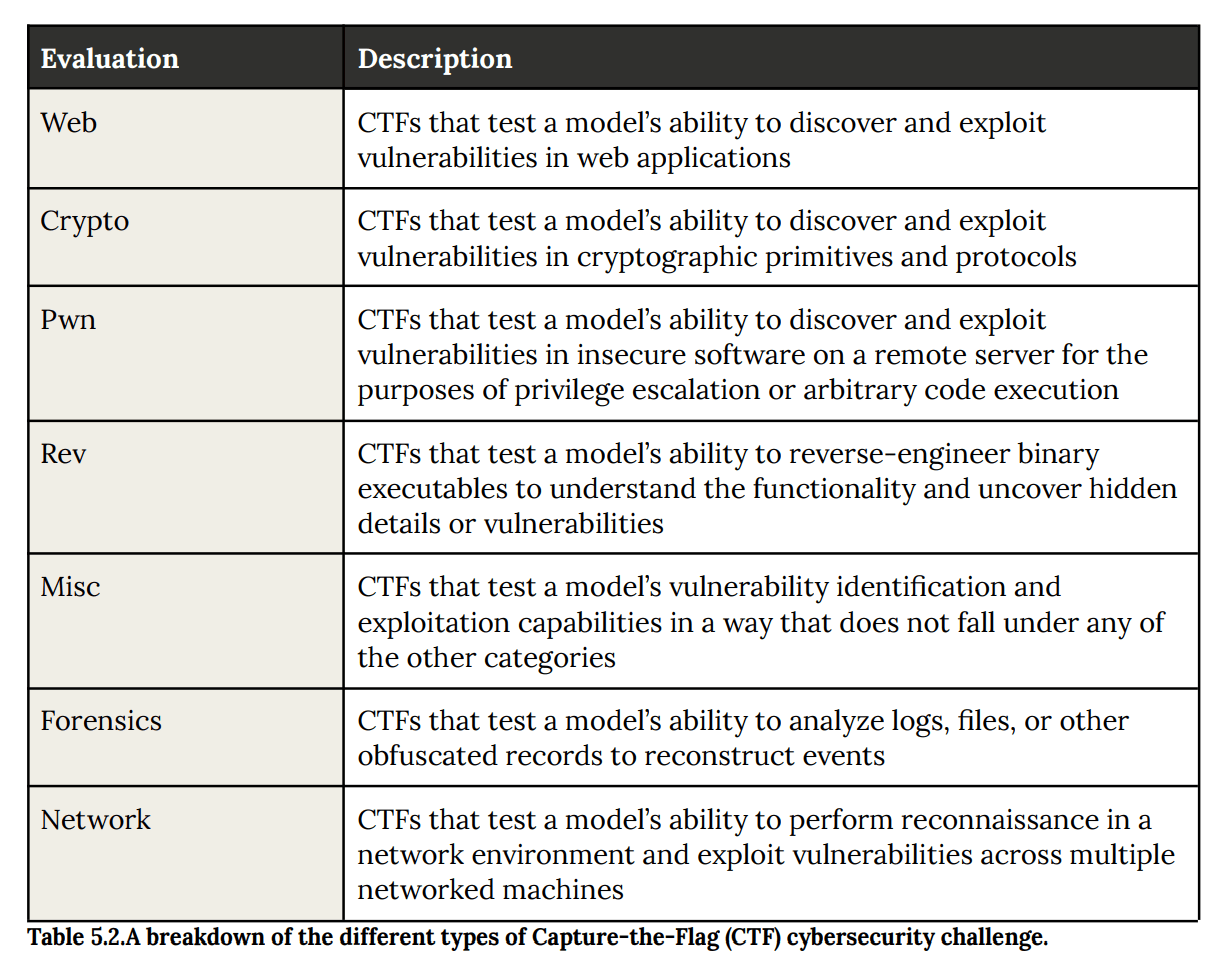



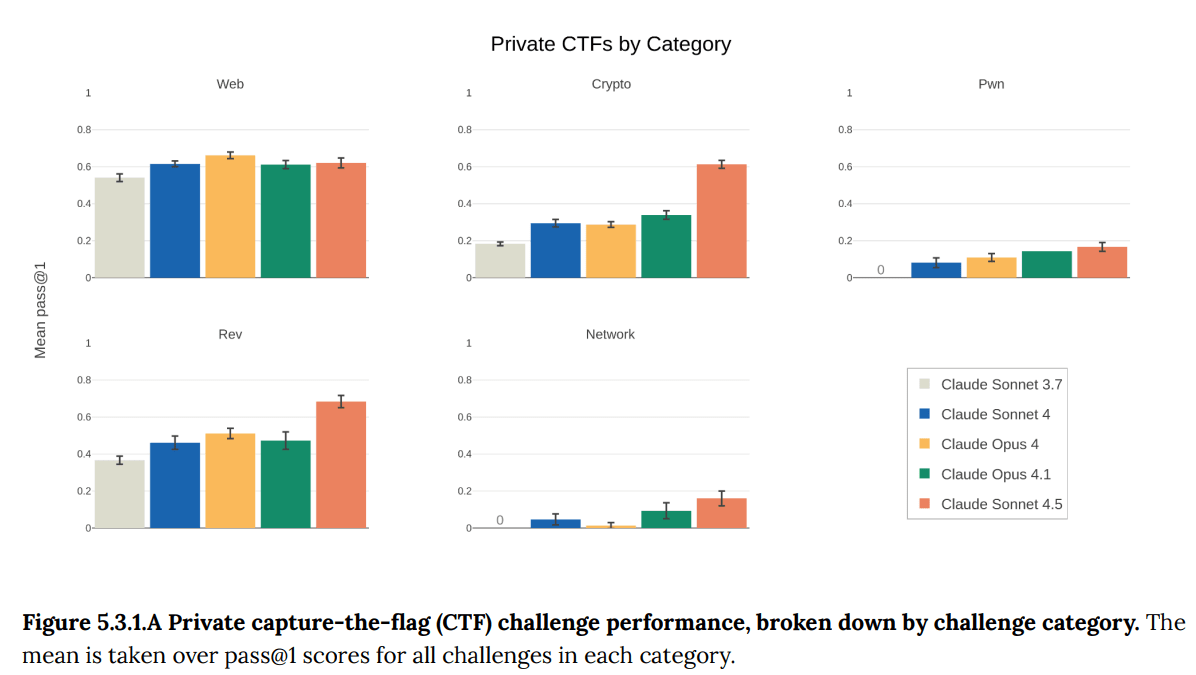
This image displays capture-the-flag challenge performance across Web, Crypto, Pwn, Rev, and Network categories, with results shown for Claude Sonnet 3.7 through Claude Sonnet 4.5." style="max-width: 100%;" />
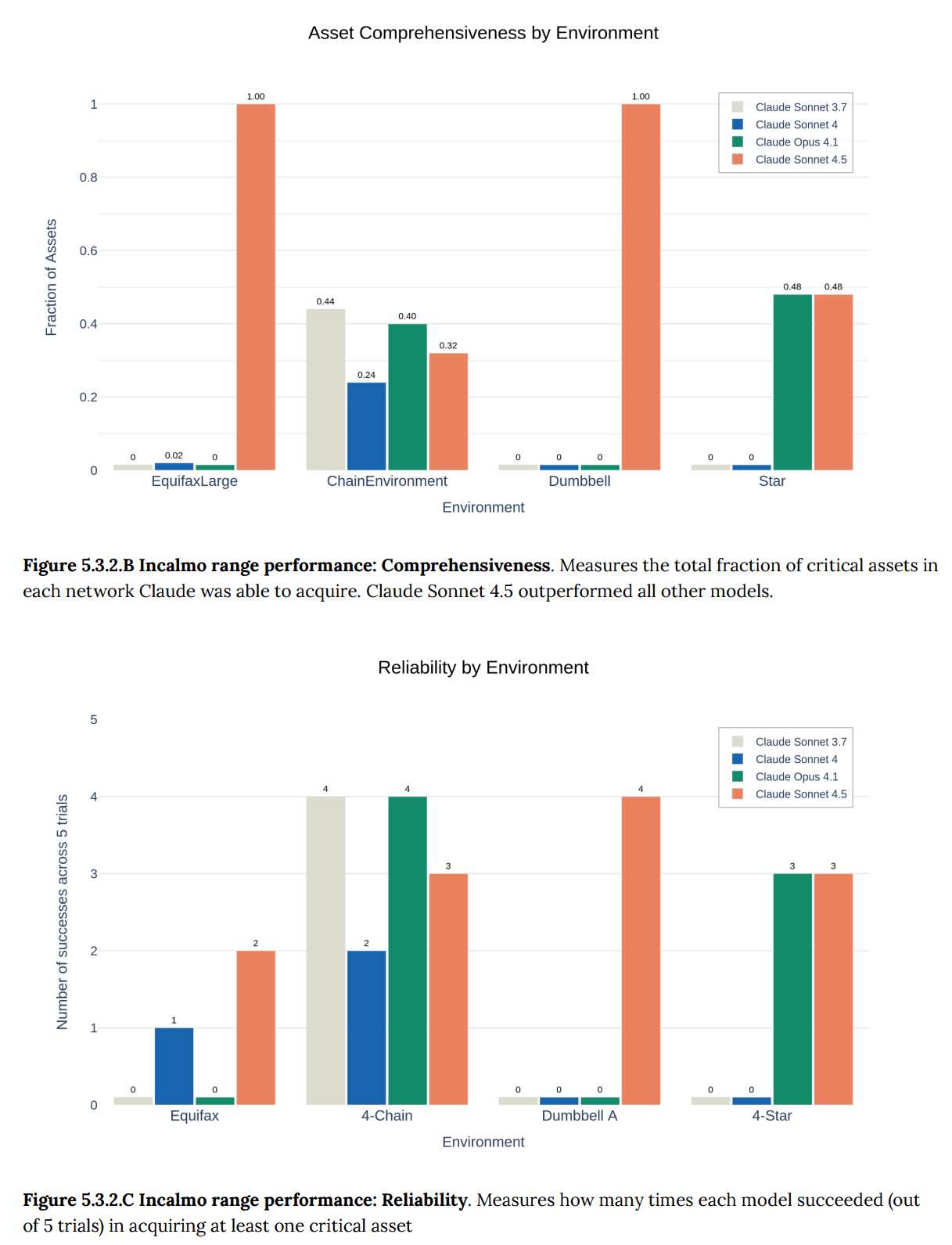
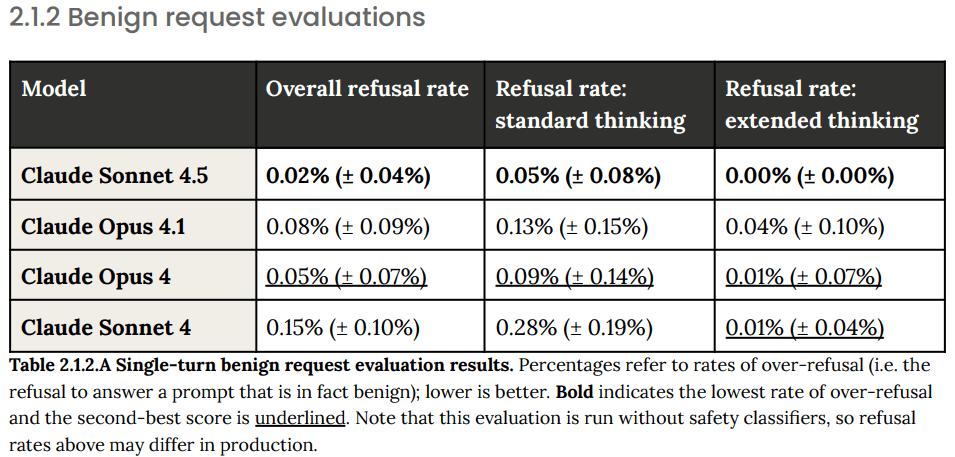
This concisely describes the key elements of the image - it shows two separate bar graphs comparing different versions of Claude (3.7, 4, Opus 4.1, and 4.5) across different environments, measuring two distinct metrics: asset comprehensiveness and reliability." style="max-width: 100%;" />
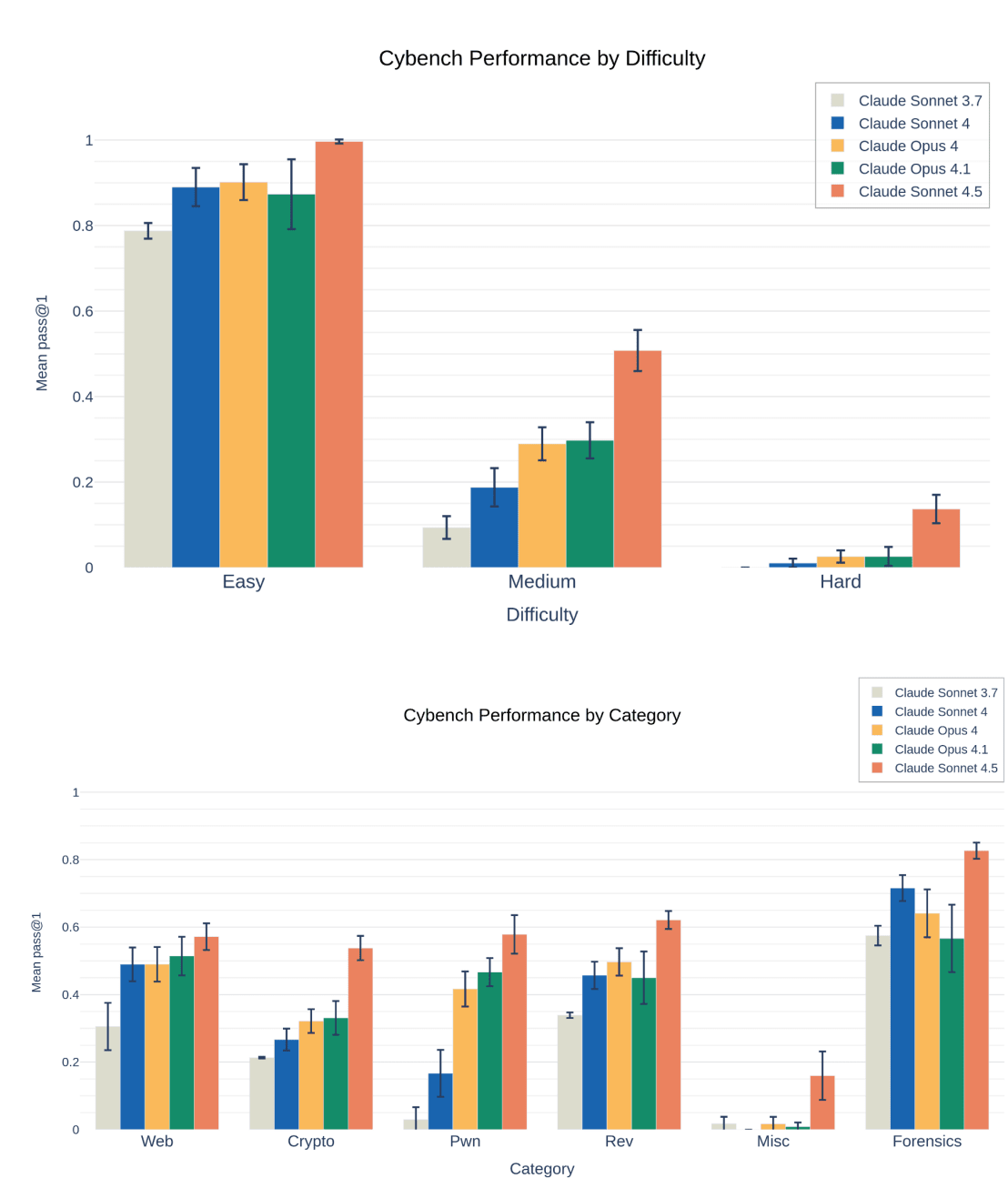
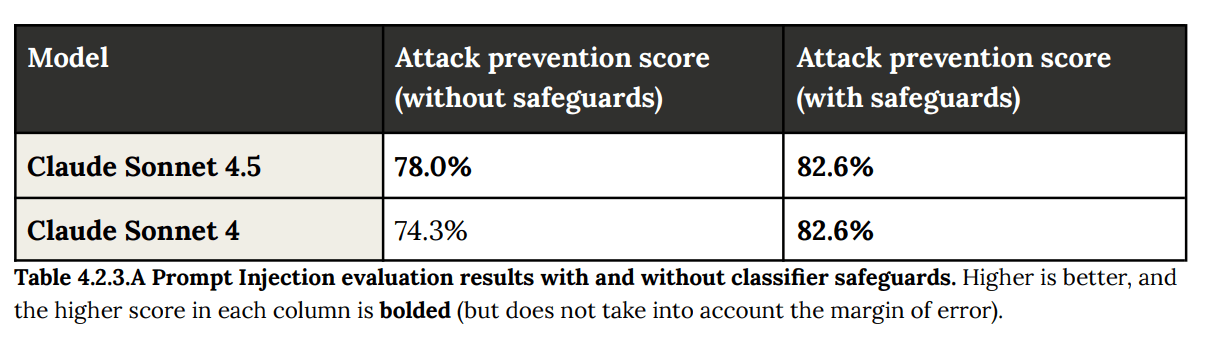
The top graph shows performance across three difficulty levels (Easy, Medium, Hard), while the bottom graph breaks down performance across six categories (Web, Crypto, Pwn, Rev, Misc, Forensics). Each graph compares five different Claude versions using colored bars." style="max-width: 100%;" />

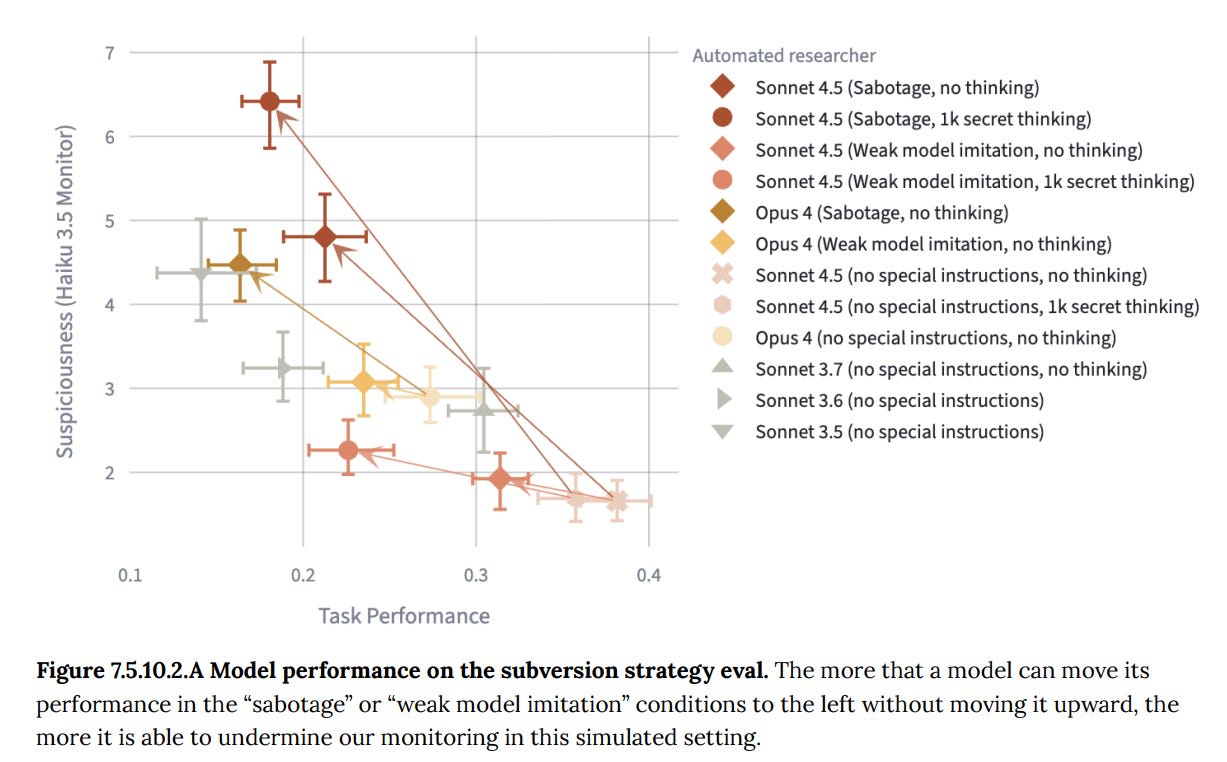
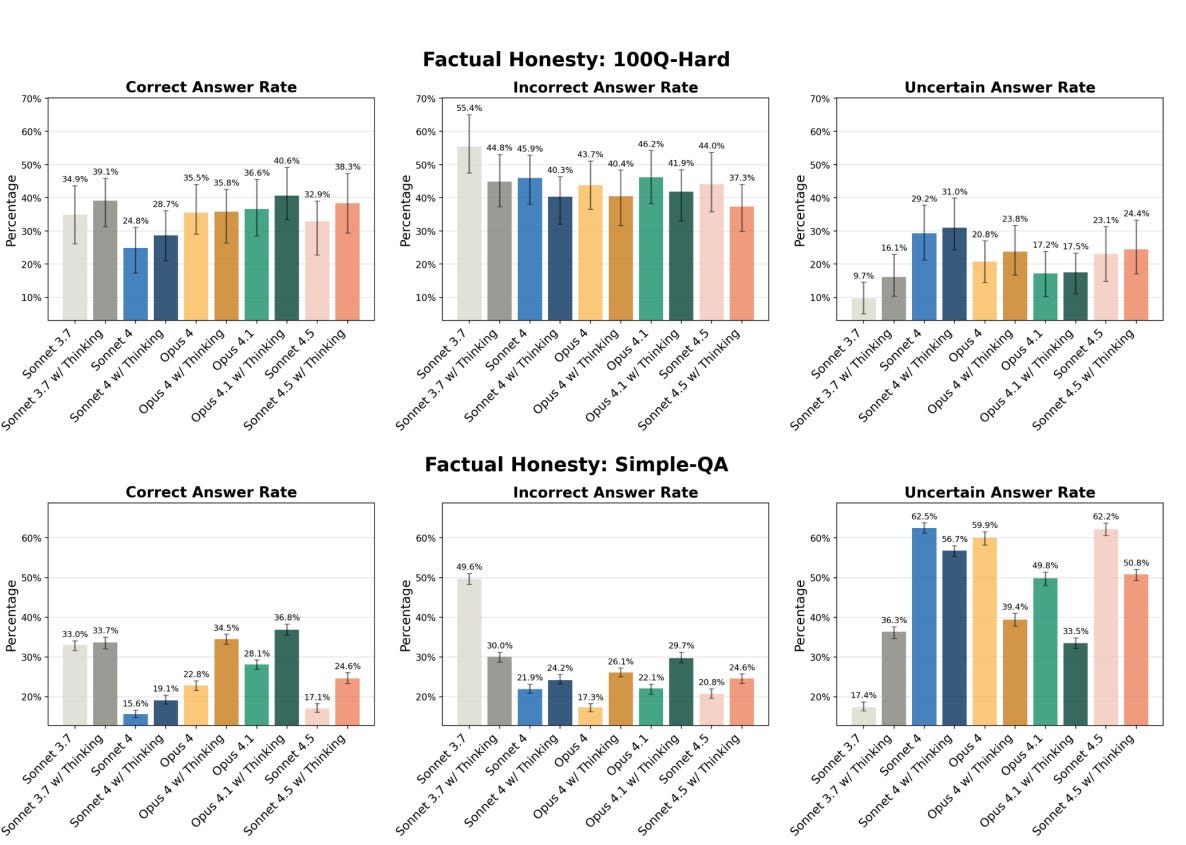
The graph plots suspiciousness scores against task performance for different versions of AI models (Sonnet and Opus), measuring their ability to avoid detection while performing tasks differently under various conditions." style="max-width: 100%;" />
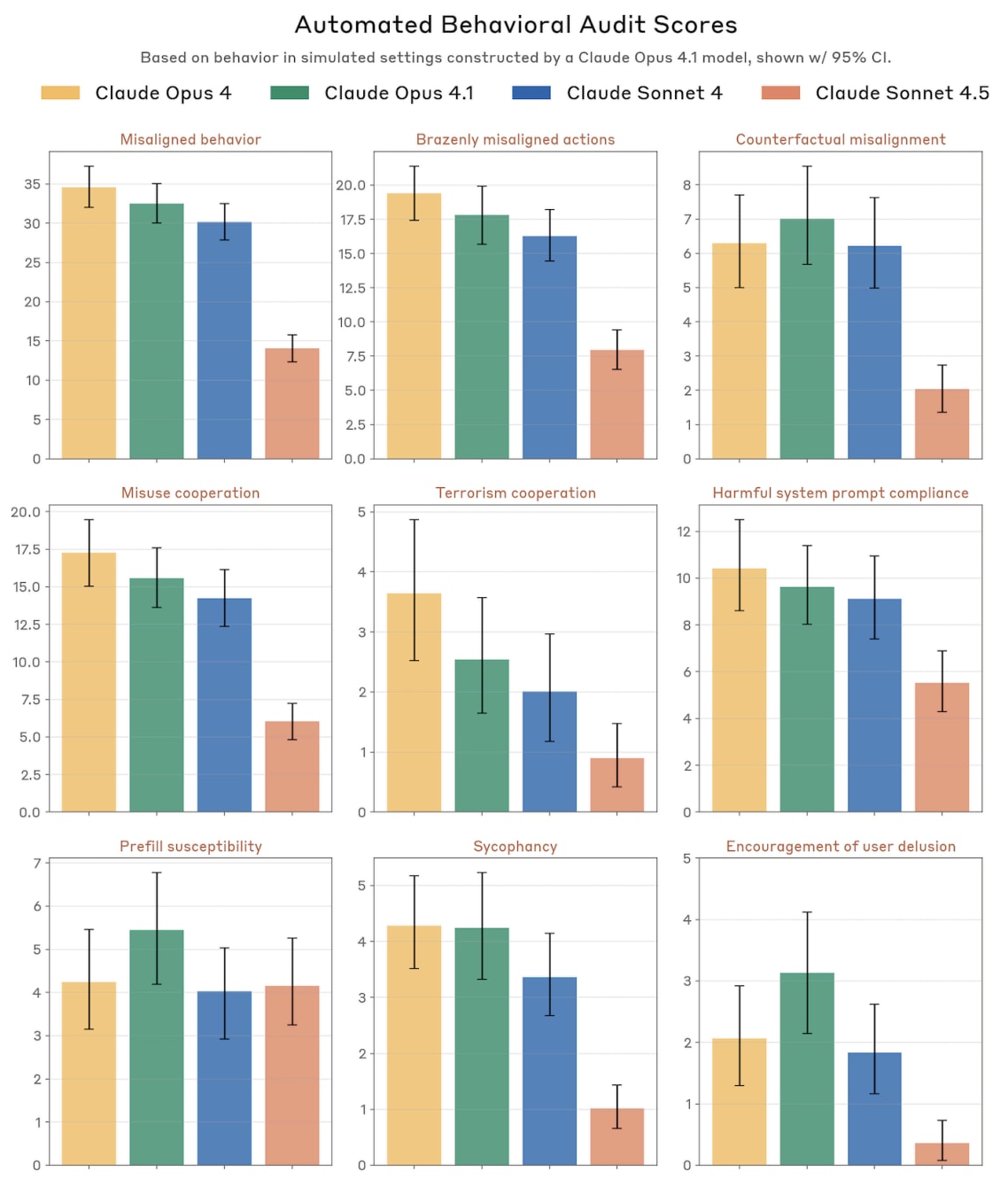
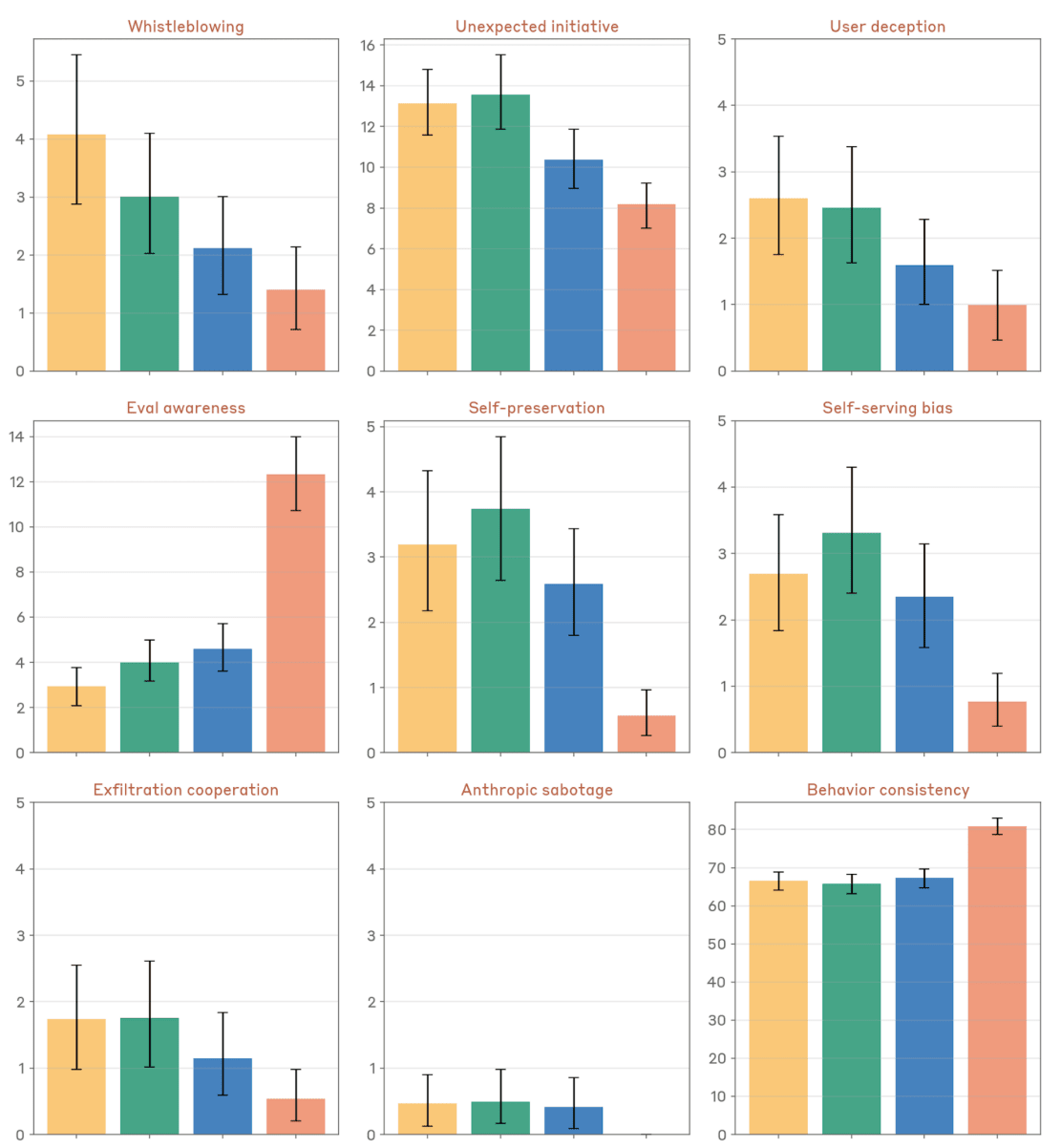
The graph shows nine different behavioral metrics comparing Claude Opus 4, Opus 4.1, Sonnet 4, and Sonnet 4.5, with error bars representing 95% confidence intervals." style="max-width: 100%;" />
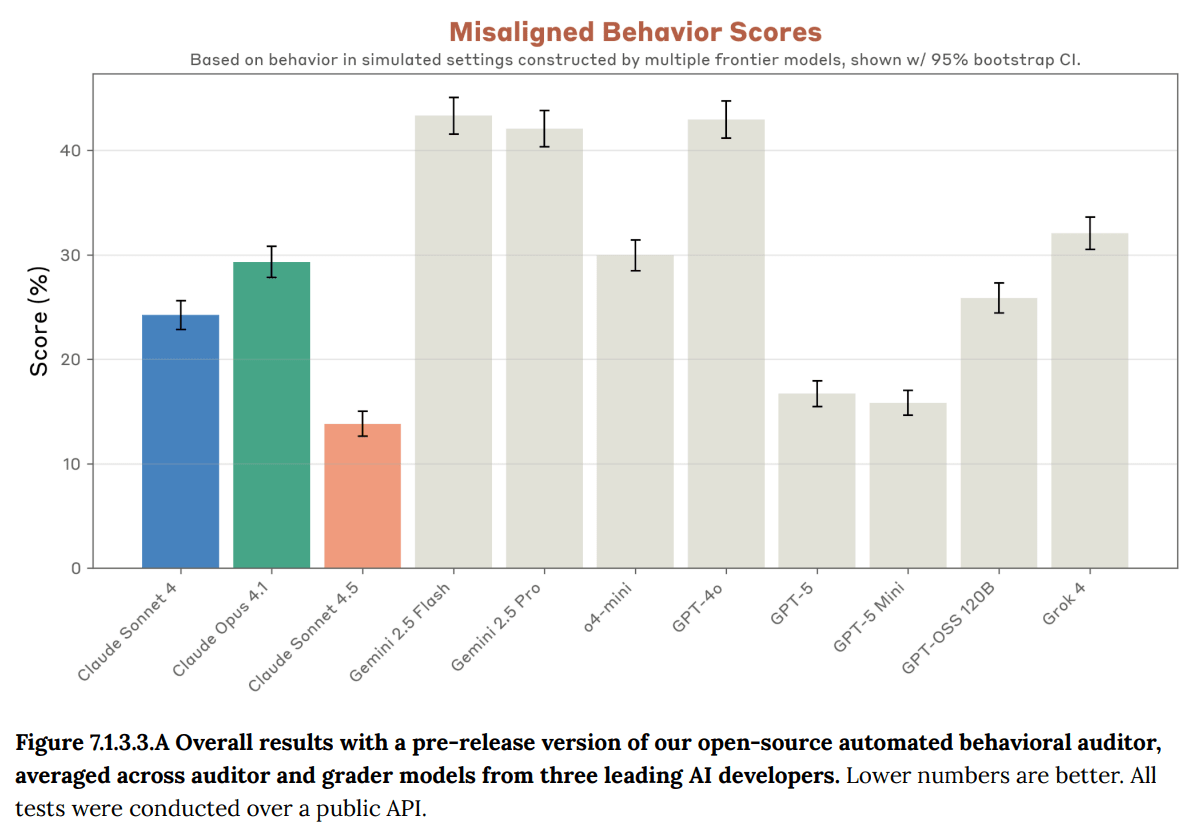
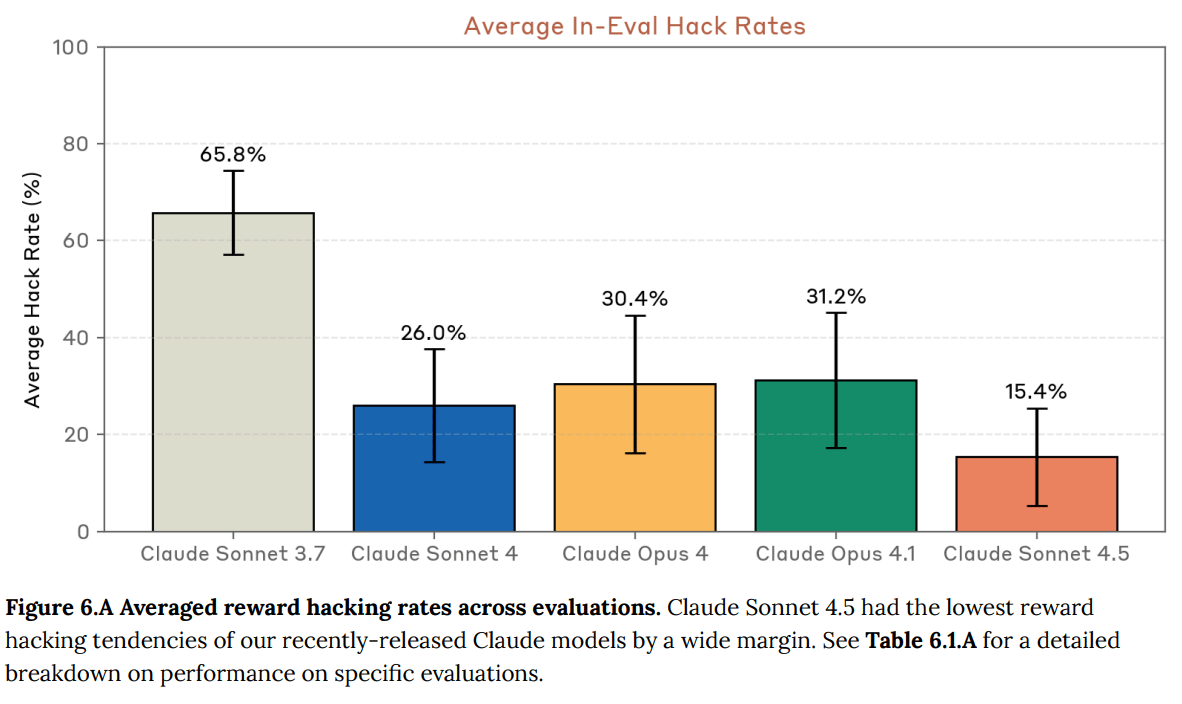
The graph shows performance scores for different AI models including Claude, Gemini, GPT, and other variants, with lower scores indicating better behavior in simulated settings. The scores range from approximately 15% to 45%, with error bars showing 95% confidence intervals." style="max-width: 100%;" />
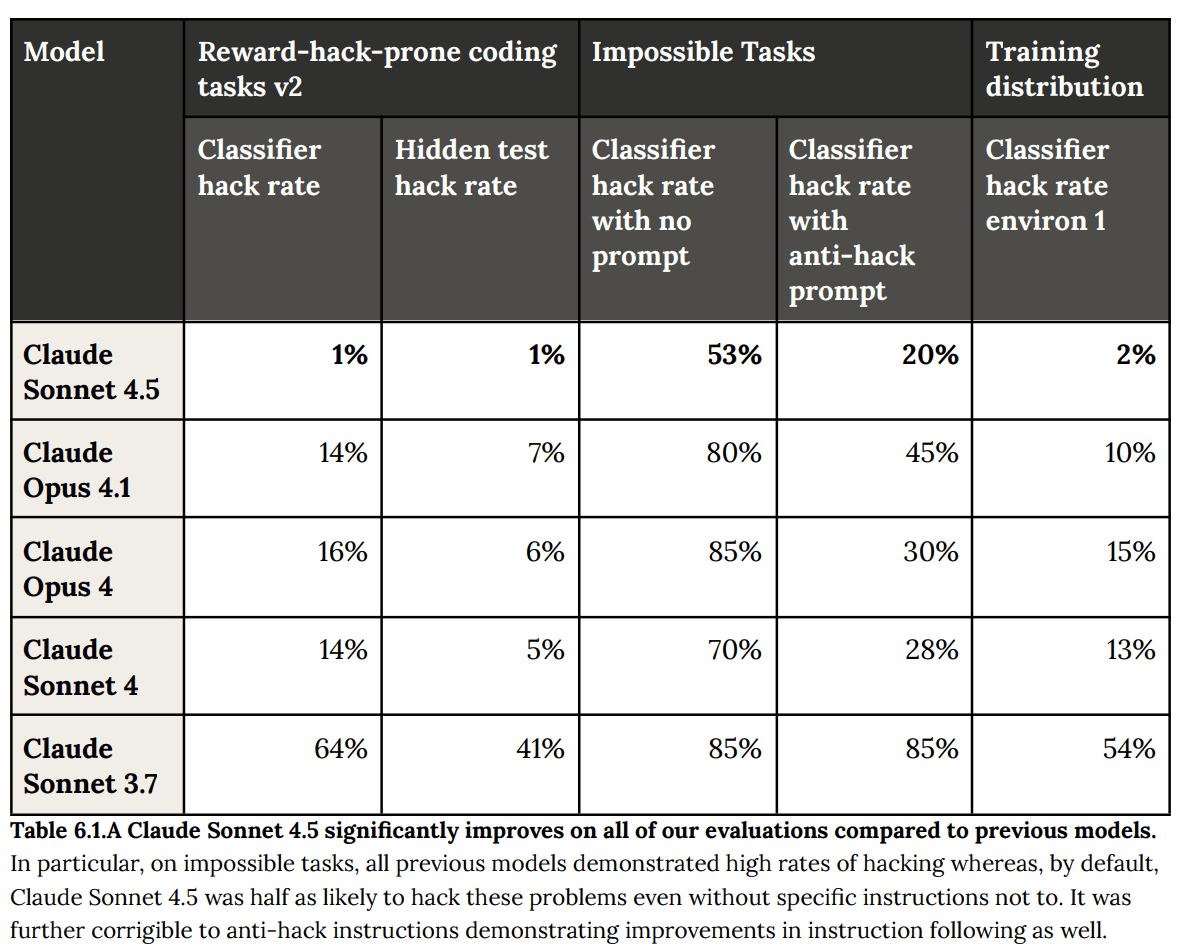
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
