Google recently came out with Gemini-2.5-0605, to replace Gemini-2.5-0506, because I mean at this point it has to be the companies intentionally fucking with us, right?
Google: Our updated Gemini 2.5 Pro Preview continues to excel at coding, helping you build more complex web apps. We’ve also added thinking budgets for more control over cost and latency. GA is coming in a couple of weeks…
We’re excited about this latest model and its improved performance. Start building with our new preview as support for the 05-06 preview ends June 19th.
Sundar Pichai (CEO Google): Our latest Gemini 2.5 Pro update is now in preview.
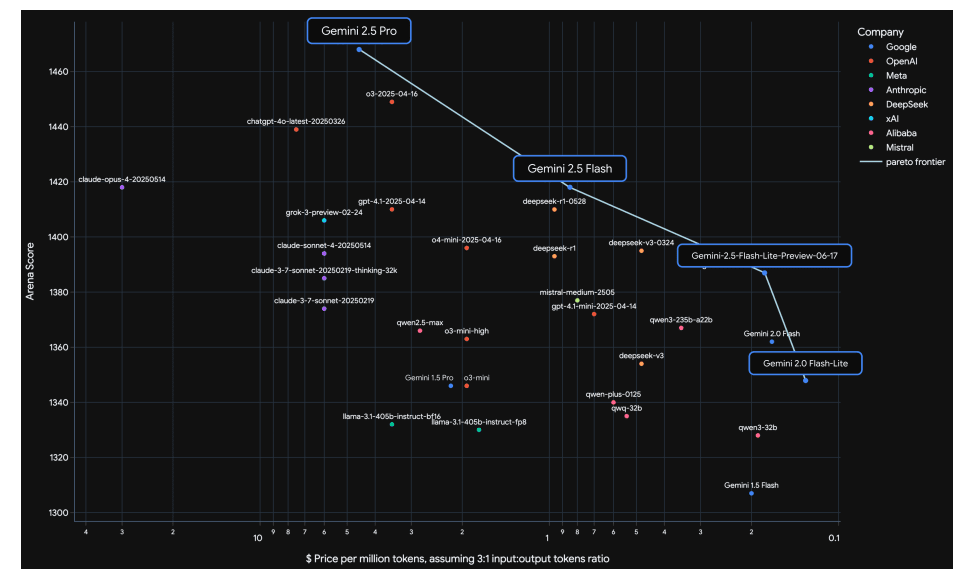
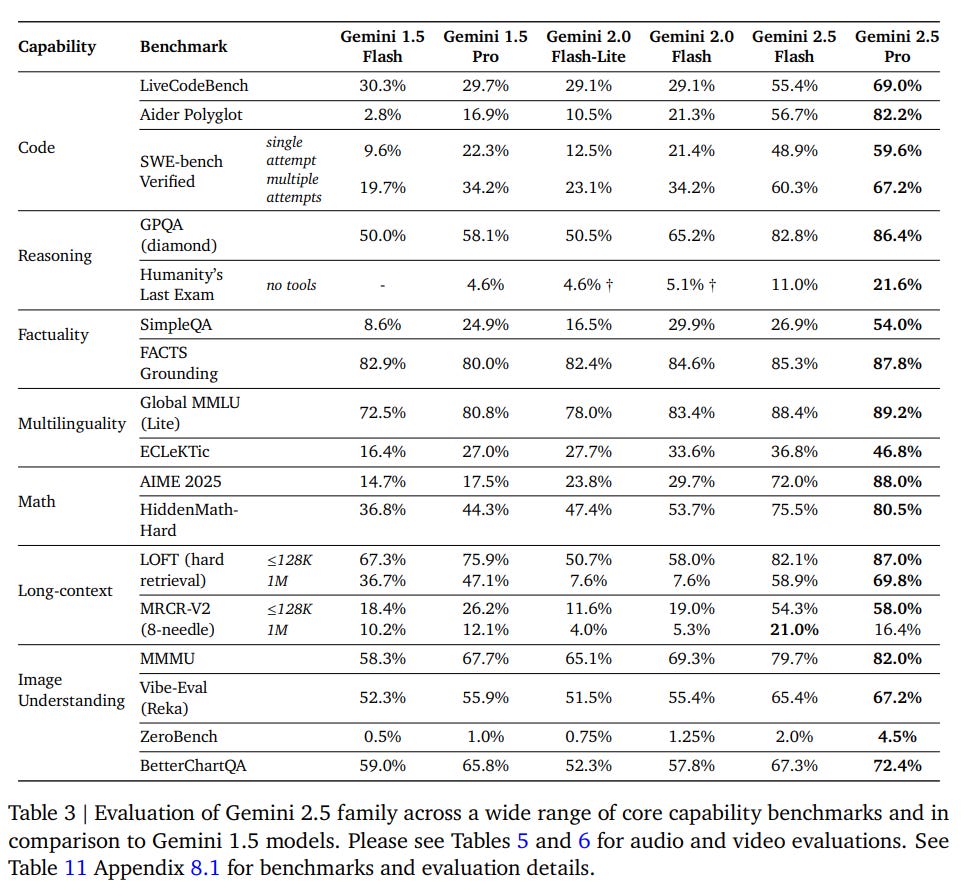
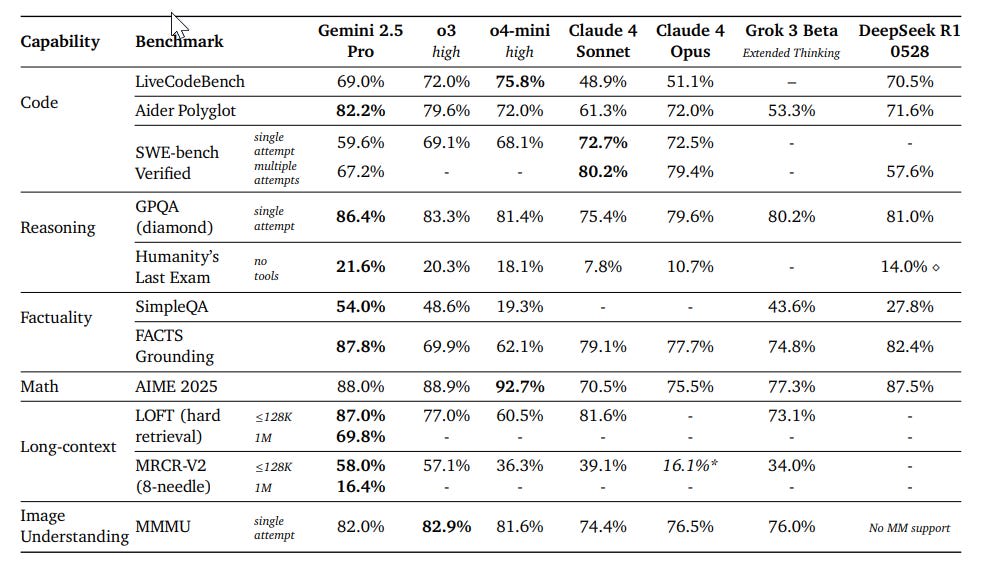
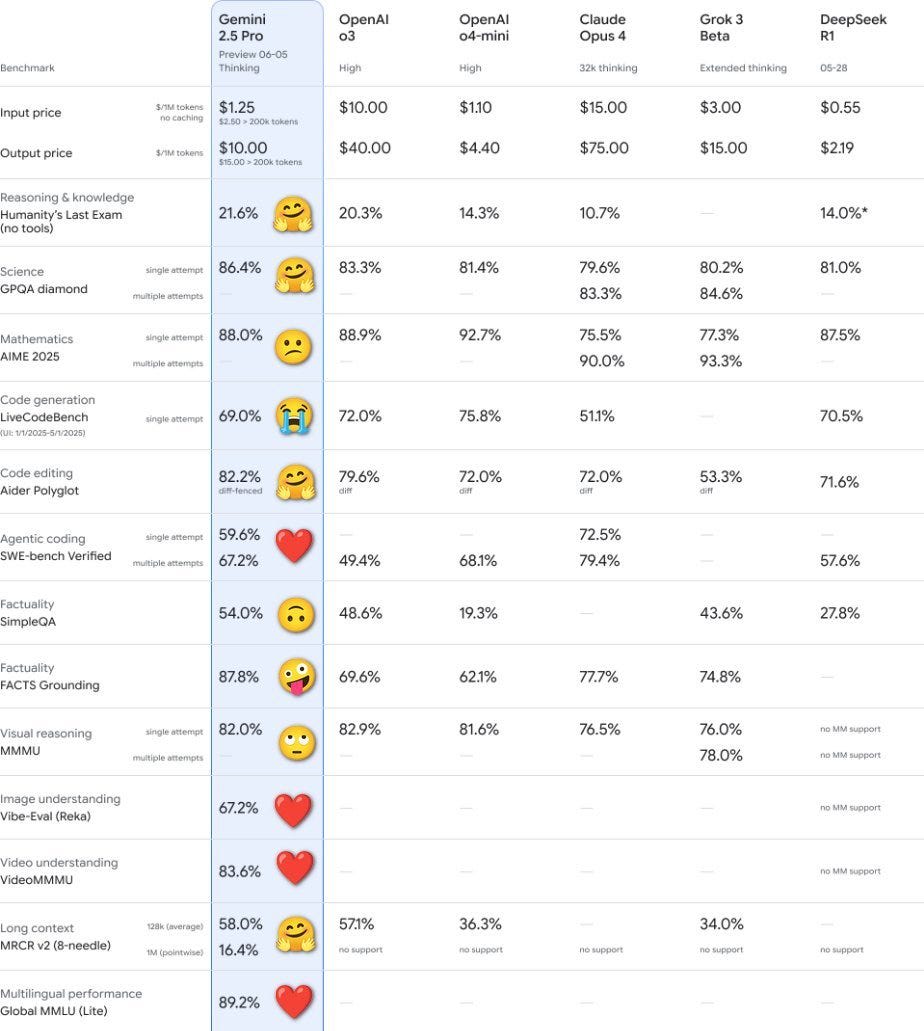
It's better at coding, reasoning, science + math, shows improved performance across key benchmarks (AIDER Polyglot, GPQA, HLE to name a few), and leads @lmarena_ai with a 24pt Elo score jump since the previous version.
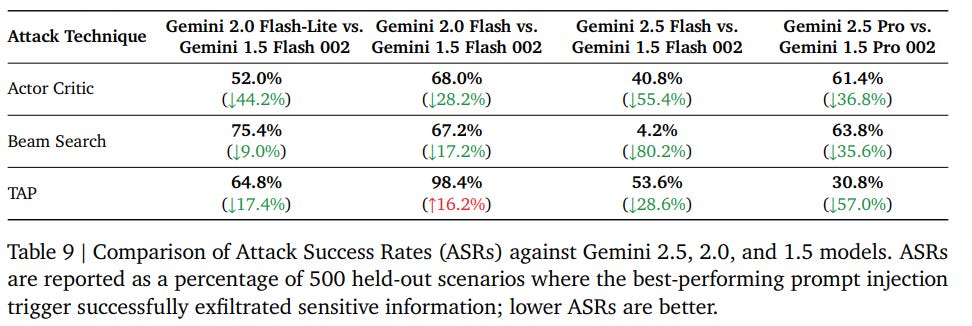
We also heard your feedback [...]
---
Outline:
(02:06) What's In A Name
(02:49) On Your Marks
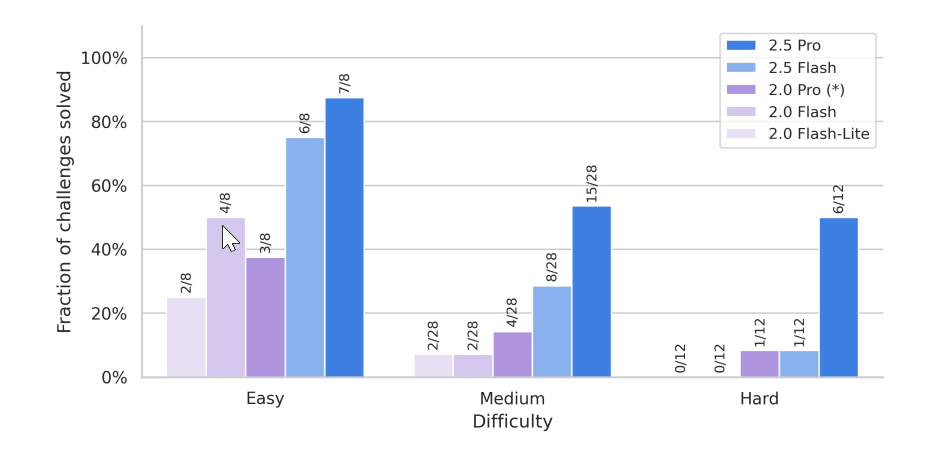
(08:05) Gemini 2.5 Flash Lite Preview
(08:24) The Model Report
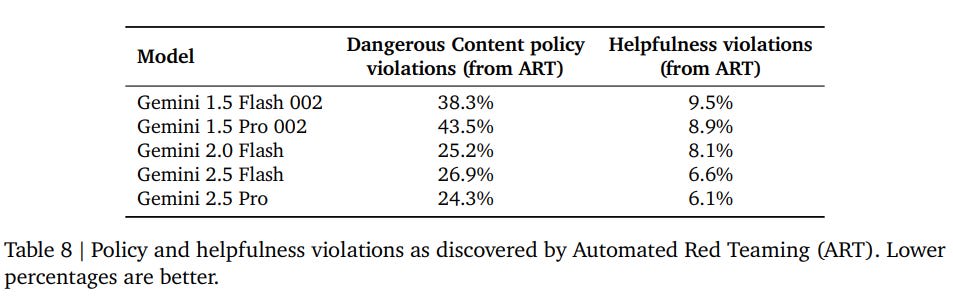
(11:33) Safety Testing
(15:17) General Reactions to Gemini 2.5-Pro 0605
(16:48) The Personality Upgrades Are Bad
(19:36) The Lighter Side
---
First published:
June 18th, 2025
Source:
https://www.lesswrong.com/posts/eJaQvvebZwkTAm5yd/gemini-2-5-pro-from-0506-to-0605
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
