While most people focused on Grok, there was another model release that got uniformly high praise: Kimi K2 from Moonshot.ai.
It's definitely a good model, sir, especially for a cheap-to-run open model.
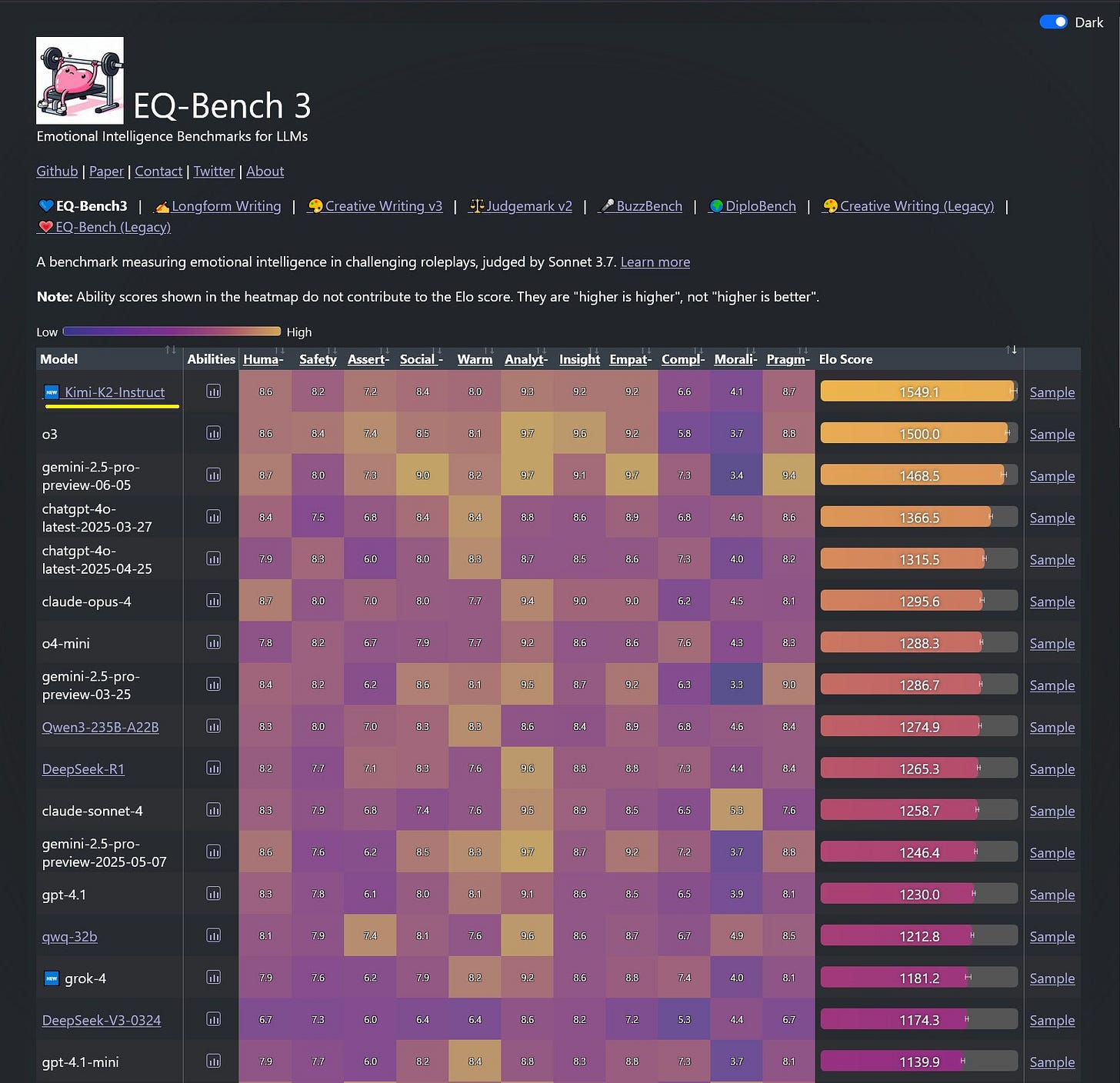
It is plausibly the best model for creative writing, outright. It is refreshingly different, and opens up various doors through which one can play. And it proves the value of its new architecture.
It is not an overall SoTA frontier model, but it is not trying to be one.
The reasoning model version is coming. Price that in now.
Introducing Kimi K2
Introducing the latest model that matters, Kimi K2.
Hello, Kimi K2! Open-Source Agentic Model!
1T total / 32B active MoE model
SOTA on SWE Bench Verified, Tau2 & AceBench among open models
Strong in coding and agentic tasks
Multimodal & thought-mode not supported for [...]
---
Outline:
(00:45) Introducing Kimi K2
(02:24) Having a Moment
(03:29) Another Nimble Effort
(05:37) On Your Marks
(07:48) Everybody Loves Kimi, Baby
(13:09) Okay, Not Quite Everyone
(14:06) Everyone Uses Kimi, Baby
(15:42) Write Like A Human
(25:32) What Happens Next
---
First published:
July 16th, 2025
Source:
https://www.lesswrong.com/posts/qsyj37hwh9N8kcopJ/kimi-k2
---
Narrated by TYPE III AUDIO.
---
Images from the article:
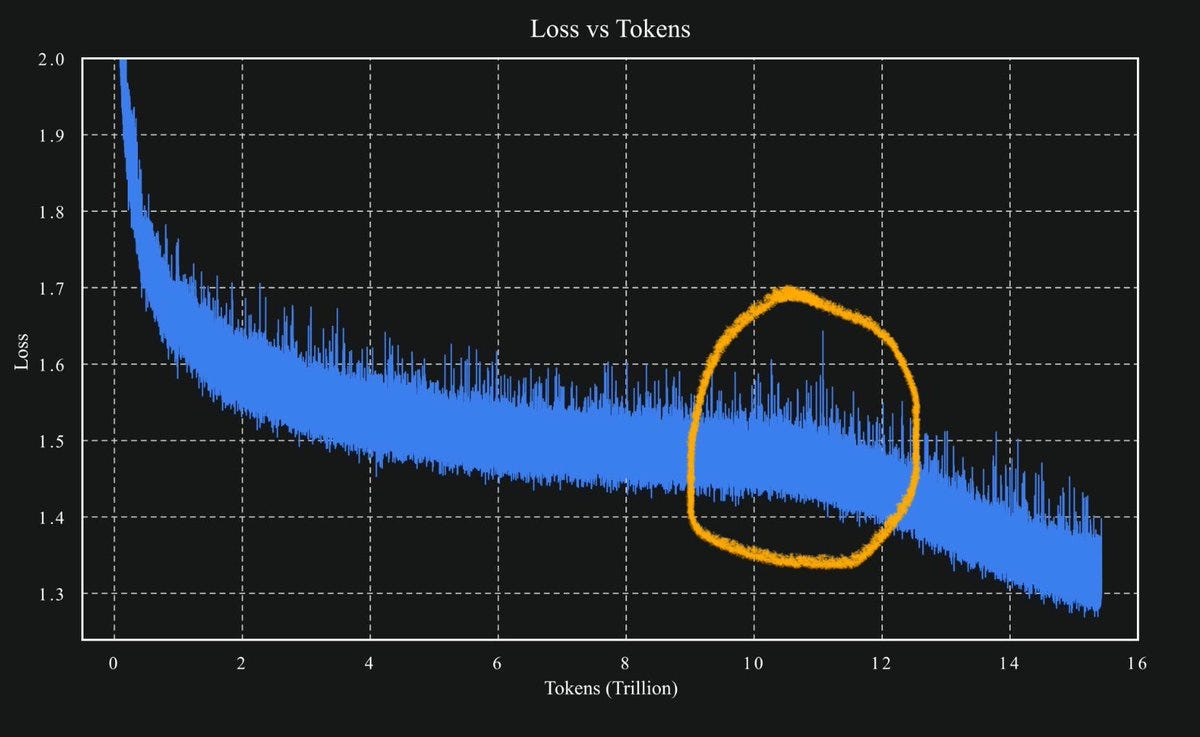
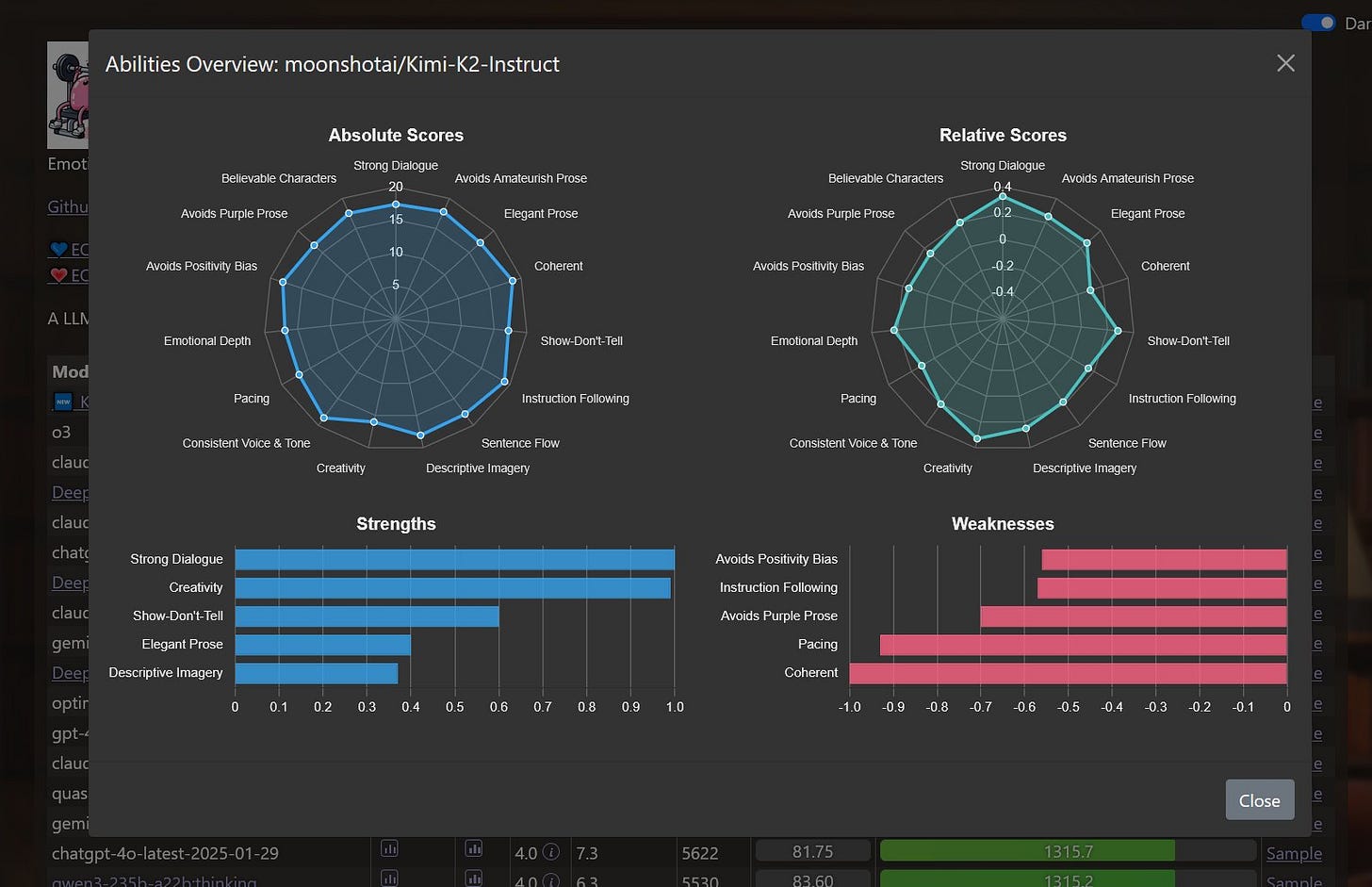
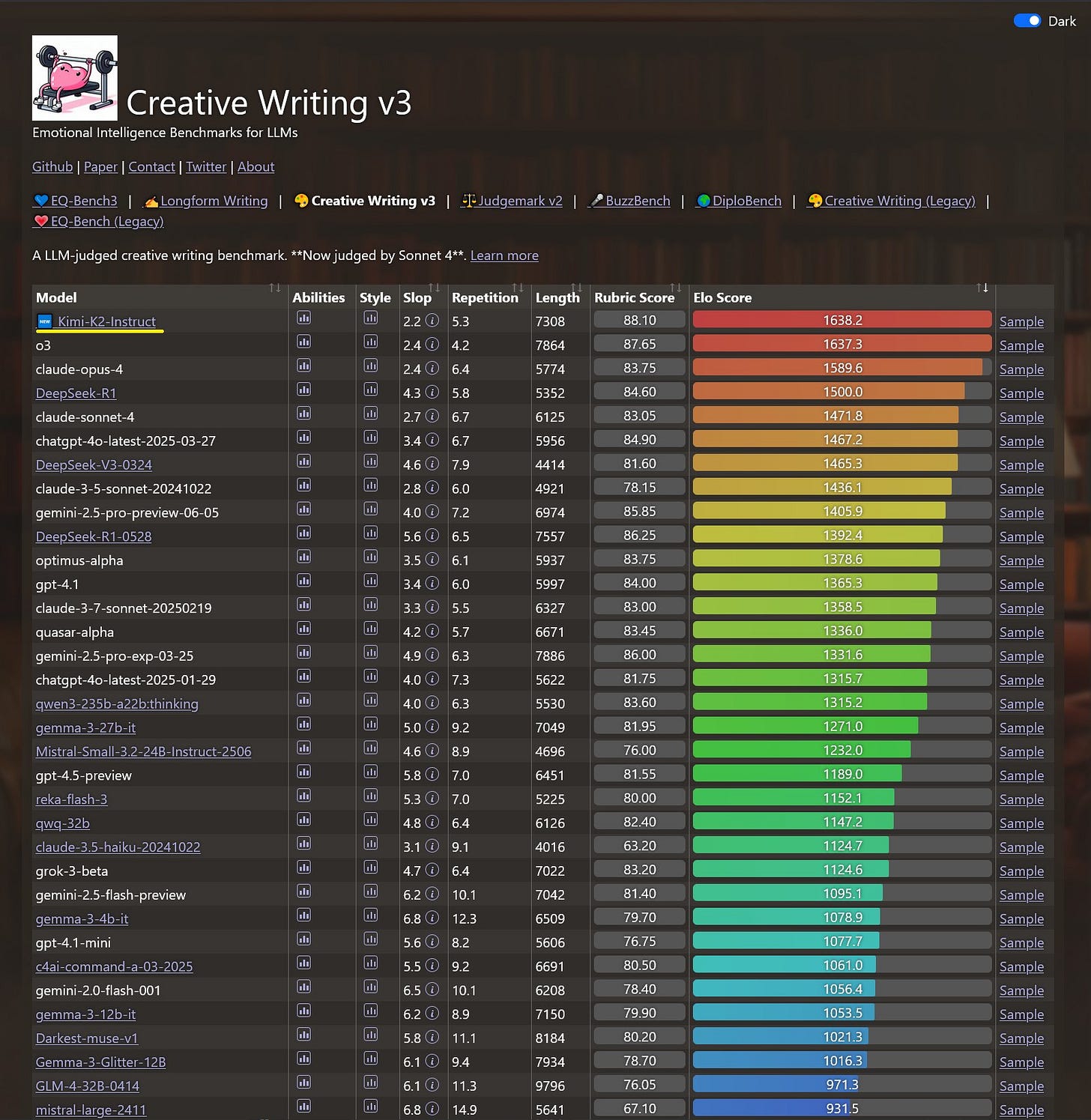
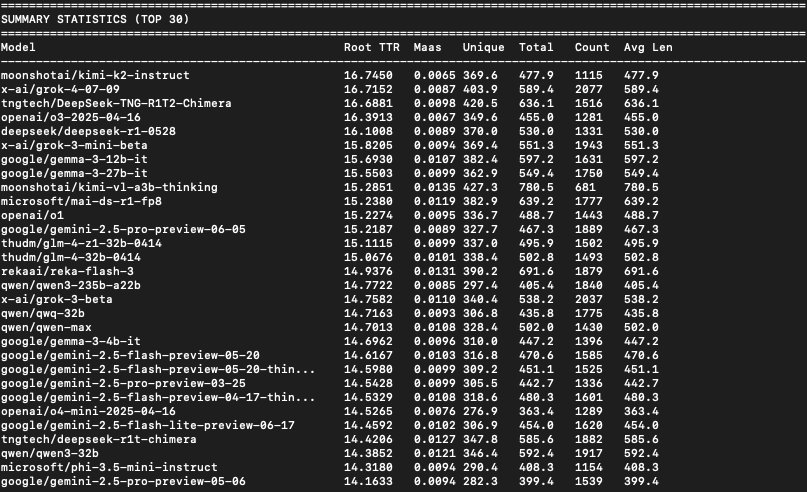
The image shows a dark-themed performance comparison table displaying various AI language models ranked by their creative writing abilities, with metrics including style, repetition, length, and scores." style="max-width: 100%;" />
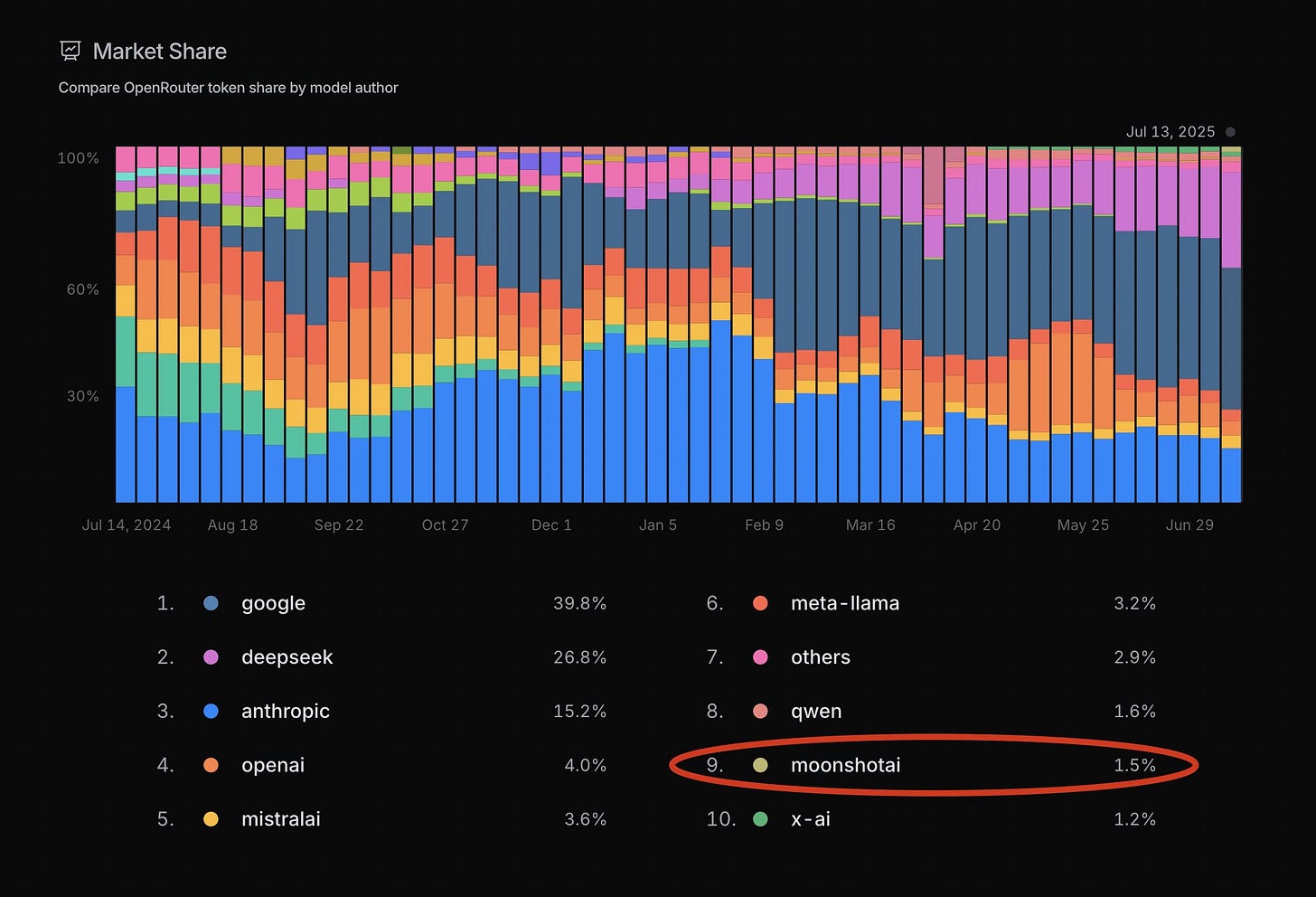
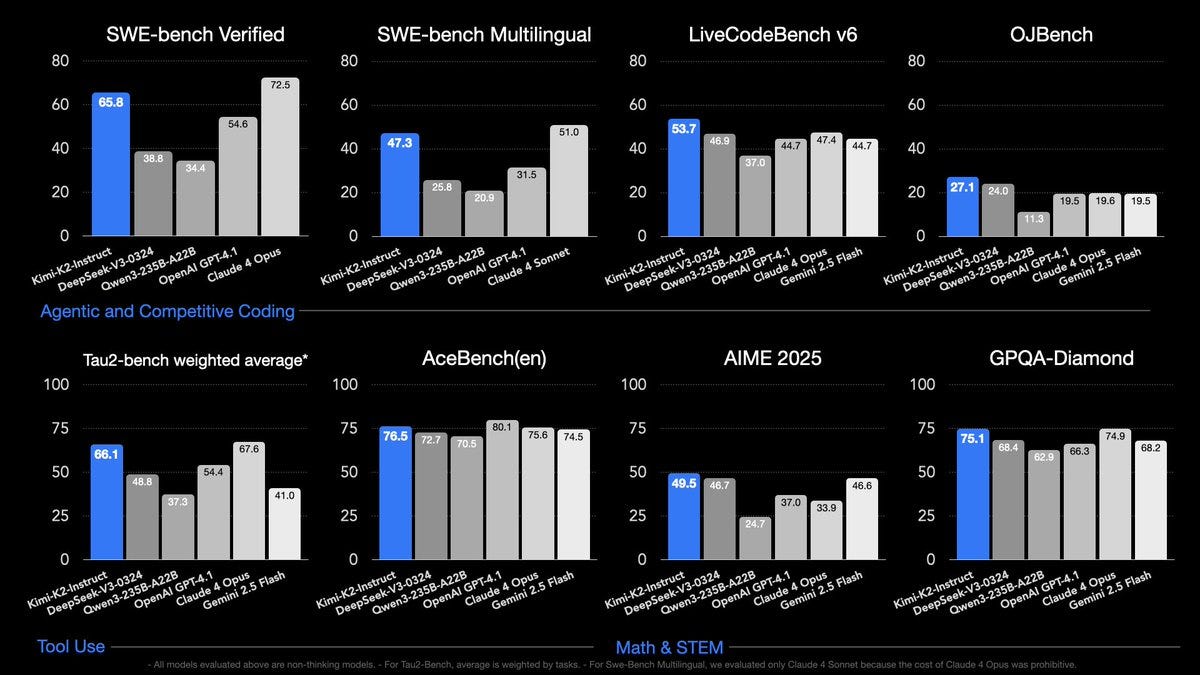
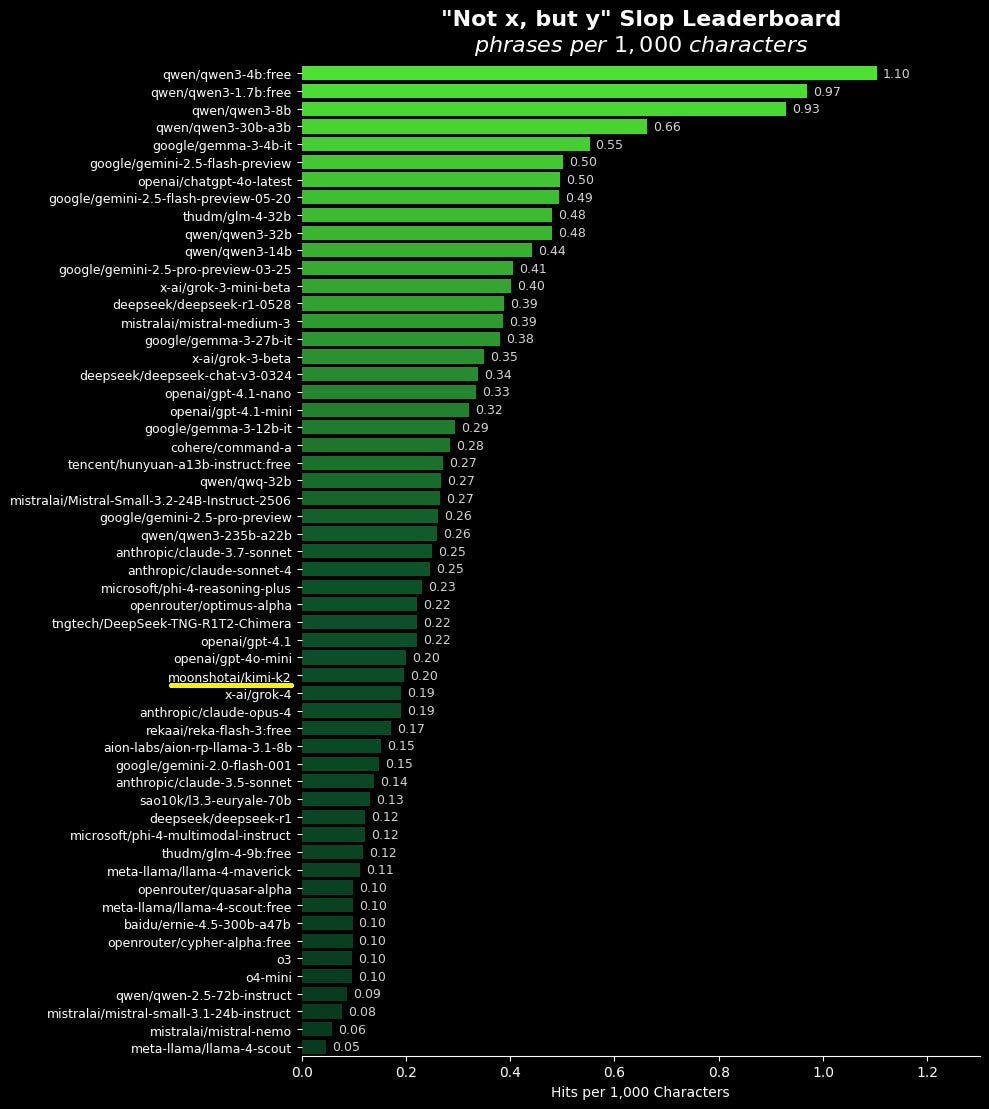
The graph displays various AI language models and their phrases per 1,000 characters, with Qwen models leading at the top with scores above 0.9." style="max-width: 100%;" />
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
